처음 스터디 주제였던 eDX의 Analyzing Big Data with Microsoft R Server 는 성공적으로 종료 되었습니다. 아래의 링크를 클릭하시면, 스터디 발표 자료를 살펴보실 수 있습니다.
|
범위
|
일자
|
발표자료
|
|
1. Introduction
|
1월 5일(목) 20:00
|
|
|
2. Reading and Preparing Data
- Reading the Data
- Preparing the Data
|
1월 12일(목) 20:00
|
|
|
3. Examining and Visualizing Data
- Examining the Data
- Visualizing the Data
|
1월 19일(목) 20:00 |
|
|
4. Clustering and Modeling
- Clustering
- Predictive Modelling
|
2월 2일(목) 20:00 |
|
|
5. Deploying and Scaling
- Deploying to SQL Server
- Working with Spark
- Wrap-up & Next
|
2월 9일(목) 20:00 |
|
자료에 대하여 궁금하신 점은 우상단 [연락처] 메뉴를 통하여 저에게 문의하여 주십시요.
Last Updated : 2017-02-16
어느새 금방 한 달이 지나간 것 같습니다.
이번 스터디에서는 아래의 내용들이 진행되었습니다.
- 후반부 주요 LAB 정리
- SQL Server 컨텍스트에서 RevoScaleR 수행
- eDX 내용 정리
- Fraud Detection 적용 예제 소개
- HDInsight Spark 컨텍스트에서 RevoScaleR 수행
- HDInsight / R Server 설정 방법
- Spark 컨텍스트에서 RevoScaleR 처리
그동안 관심 가져주시고, 성공적으로 종료되도록 도와주신 많은 여러분들께 진심으로 감사드립니다.
이어지는 뒷풀이 모임에서, 다음 스터디 주제가 "Power BI"로 결정되었습니다.
최초 클라우드 Hadoop 쪽으로 계획이 있었으나, 보다 실용적인 주제로 변경하자는 의견이 대부분이어서 논의 끝에 "Power BI"가 주제로 선정되었습니다.
다음주 한 주간 컨텐츠와 일정을 정리한 이후에, 2월 22일 수요일 부터 매주 수요일에 새로운 스터디를 시작할 계획이며 별도 공지를 드릴 예정입니다.
김환태
짧지 않은 설연휴를 마치고 오래간 만에 4차 모임을 가졌습니다. 메인 주제인 Machine Learning Topic이 본격적으로 다루어 졌으며, 이주경님과 김은정님께서 각각 RevoScaleR 패키지를 사용하는 Clustering과 Predictive Modelling에 대해서 알기 쉽게 잘 설명해 주셨습니다.
주로 논의되었던 Clustering과 Linear Regression 모델은 특히 RevoScaleR 적용에 있어서 대량 병렬 연산 기능이 돋보이는 항목이었으며, 실전에서 아주 유용하게 쓰일 수 있을 트릭으로 초기 소량 데이터로 클러스터 center들을 가늠한 이후 대용량의 본 데이터 적용하는 것 같은 흥미로운 내용들이 다루어 졌습니다.
본격적인 개발 부분은 오늘로서 어느 정도 마무리가 되었���며, 차주는 SQL Server 및 Spark에 배포하는 내용을 중심으로 이번의 스터디 과정을 마무리 하고자 합니다.
차주는 스터디 종료 후, 간단한 Beer와 함께 이후 스터디 내용과 일정을 논의드리고자 하오니 많은 관심 부탁드립니다.
DI Study는 열린 스터디로 누구나 참여하실 수 있습니다.
오늘도 수고 많으셨습니다.
이번 3차 모임에서는 추운 날씨 탓인지 시작 이래 가장 적은 인원이 참석하셨습니다.(총 6명) 그렇지만 내용은 회를 거듭할 수록 충실해 지고 있다는 느낌입니다. 꼼꼼하게 내용을 챙겨서 설명해 주신 한석진 부장님, 정말 감사드립니다!
우선 지난 시간까지의 주요 내용들을 LAB 1을 통해 간단히 복습하고, 본격적인 데이터의 탐색과 시각화 작업들에 대한 설명과 시연이 이어졌습니다. 뉴욕시의 맨해튼 지역의 6개월간의 옐로우캡 택시 운행 정보에 대하여, 분석 포인트를 바꾸어 가면서 단계별로 필요한 factor를 정리해 가면서 차분하게 RevoScaleR에서의 데이터 가공 방법을 단계적으로 제대로 볼 수 있었던 기회 였습니다.
개인적으로는 독습으로 진행할 때 어렴풋하게 두리뭉실 넘어갔던 내용들을 질문 및 토의를 통하면서 명확하게 할 수 있었던 점이 좋았던 것 같습니다.
차주는 설연휴 주간으로 스터디가 없으며, 모든 일정을 1주일씩 뒤로 조정하기로 하였습니다. 다음 모임에서 발표는 이주경님(Clustering))과 김은정님(Predictive Modeling)이 수고해 주시기로 하였습니다.
해당 챕터는 Machine Learning의 핵심 내용이므로 놓치지 마시기 바랍니다.
DI Study는 열린 스터디로 누구나 참여하실 수 있습니다.
오늘도 수고 많으셨습니다.
안녕하세요,
이번 2차 모임에서는 모두 10분(오프라인 6명 온라인 4명)이 참석하여 주셨습니다. 갑작스러운 추위에도 시간을 내어 참석하여 주신 분들께 진심으로 감사드립니다. 1회 모임과 마찬가지로 온라인 1시간 진행 이후에, 오프라인에서도 역시 1시간 정도 발표 내용 및 실무 연계에 대한 주제로 추가 토의가 이루어 졌습니다.
데이터 분석에서 데이터의 준비 및 가공 과정에는 가장 많은 노력과 시간이 들어갑니다. 오늘 살펴본 내용은 RevoScaleR 패키지의 rx 함수들을 사용하여, 어떻게 이러한 처리들을 진행하는 지에 대하여 개념을 잡아갈 수 있었던 시간이었던 것 같습니다.
안정적이고 충실하게 준비해 오신 이주경 님의 발표 덕분으로 스터디 진행에 대한 틀이 어느 정도 잡혀가는 느낌이며, 온라인 발표 이후에 최고의 R 강사이신 이후선 대표님의 소중한 즉석 강의도 무척 좋은 시간이었습니다.
차주 발표는 마이크로소프트의 한석진 부장님께서 'Examining the Data' 파트를 맡아 주시기로 하였고, 나머지 'Visualizing the Data' 부분은 발표하실 지원자를 찾는중입니다. 발표 의사가 있으신 분은 저에게 알려 주십시요. eDX 해당 내용을 30분 정도로 요약하여 주시면 됩니다. ^^;
오늘 발표된 내용에 대한 질문은 본 후기 게시판의 댓글 또는 저에게 이메일로 알려주시면, 정리하여 블로그에 반영하도록 하겠습니다.
차차주는 설연휴여서 스터디 모임 일정에 변경이 있을 수 있습니다. 이 부분은 다음 모임에서 결정하여 공지 드리도록 하겠습니다.
모두 수고 많으셨습니다.
안녕하세요,
이번 1차 모임에서는 모두 23분(오프라인 8명 온라인 15명)이 참석하여 주셨습니다. 온라인 1시간 진행 이후에, 오프라인에서도 1시간 정도 더 토의가 이루어 졌습니다. eDX 내용 이외에 실무적인 주제와 몇가지 Power BI와 연계된 시각화 및 데이터 검증 방안 등이 논의되었습니다. 이번에는 진행이 미숙하여 스터디로 얻을 수 있는 네트워킹 시간이 미흡했는데, 다음 모임에서는 보완될 수 있도록 고민중입니다.
아래 모임이후 논의되었던 몇 가지 내용들을 정리하여 공유 드립니다.
1. Microsoft R 의 가격은 어떻게 되는지?
2. 개발 및 테스트를 위힌 Azure 클라우드상의 환경 셋팅 방법은?
3. 기존 작성하였던 Base R 코드에서 ScaleR로 변경해야 할 때, 어느 정도 작업이 필요한지?
- 상황에 따라 다르며, 대용량 빅데이터 처리 또는 기존 R 프로그램의 성능 향상을 위한 목적일 경우, 데이터 ingest 및 조작, 처리, 모델링 단계별로 병렬 처리가 가능한 ScaleR의 rx로 시작되는 Function들이 Base R 대비 향상된 Function 적용을 검토될 수 있으며, 특정 Function들은 입력 및 출력으로 data.frame이 아닌 .xdf 파일로 변경이 필요할 수도 있음
- Comparison of Base R and ScaleR Functions : 기존 R 코드를 기반으로 ScaleR로 전환시 참조 (영문)
1월 12일 다음 스터디에서 뵙겠습니다!
김환태
2017년도 1차 스터디 모임을 다음과 같이 진행합니다. 공지 드린 바와 같이 온라인 중계를 겸하여 진행되므로 아래 참석 링크를 통하여 동일한 시간에 참석 가능합니다. 저는 당일 19시 부터 현장에 대기하고 있을 예정이므로, 오프 라인으로 참석 하실 분들은 12층에 오셔서 저에게 전화 주시면 됩니다. (010-8957-8041 / 김환태)
온라인 중계 내용의 녹화는 지난 테스트 미팅에서 별 문제 없이 진행되었으나, 강의가 아닌 스터디인 성격상 그대로 공개 하기에는 내용에 군더더기 부분들이 많아서, 스터디 동영상 공유는 진행하지 않을 계획입니다. 발표 자료 및 기타 유용한 동영상은 스터디 종료 이후에 블로그를 통해서 공유하도록 하겠습니다.
그럼, 목요일 저녁에 뵙겠습니다.
지역(neighborhoods) 조사
"~ ." 파라미터를 rxSummary 함수에 전달하여, 데이터 상의 모든 컬럼에 대한 요약 정보를 얻을 수 있습니다.
system.time(
rxs_all <- rxSummary( ~ ., nyc_xdf)
)
Rows Processed: 69406520
user system elapsed
0.05 0.02 85.16
예를 들자면, 데이터에서 숫자와 관련된 열에 대한 요약은 rxs_all의 sDataFrame이라는 항목 아래의 저장됩니다.
Name Mean StdDev Min Max ValidObs
1 VendorID NA NA NA NA 69406520
2 tpep_pickup_datetime NA NA NA NA 0
3 tpep_dropoff_datetime NA NA NA NA 0
4 passenger_count 1.660674 1.310478 0.0000 9.0000 69406520
5 trip_distance 4.850022 4044.503422 -3390583.8000 19072628.8000 69406520
6 pickup_longitude -72.920469 8.763351 -165.0819 118.4089 69406520
MissingObs
1 0
2 0
3 0
4 0
5 0
6 0
만약 우리가 데이터의 각 factor 열에 대한 level 수를 보여 주는 단방향 테이블을 원한다면, rxs_all을 참조하여 얻을 수 있지만, 특정 factor 열과 다른 factor열의 조합 별로 집계한 수를 보여주는 두방향의 테이블을 보려고 한다면, 올바른 수식을 요약 함수에 전달하는 것이 필요합니다. 여기에서는 rxCrossTabs 함수를 사용하여 한 지역에서 다른 지역으로 이동하는 횟수를 구합니다.
nhoods_by_borough <- rxCrossTabs( ~ pickup_nhood:pickup_borough, nyc_xdf)
nhoods_by_borough <- nhoods_by_borough$counts[[1]]
nhoods_by_borough <- as.data.frame(nhoods_by_borough)
# get the neighborhoods by borough
lnbs <- lapply(names(nhoods_by_borough), function(vv) subset(nhoods_by_borough, nhoods_by_borough[ , vv] > 0, select = vv, drop = FALSE))
lapply(lnbs, head)
[[1]]
[1] Albany
<0 rows> (or 0-length row.names)
[[2]]
[1] Buffalo
<0 rows> (or 0-length row.names)
[[3]]
New York City-Bronx
Baychester 125
Bedford Park 1413
City Island 52
Country Club 354
Eastchester 98
Fordham 1243
[[4]]
New York City-Brooklyn
Bay Ridge 3378
Bedford-Stuyvesant 54269
Bensonhurst 1159
Boerum Hill 76404
Borough Park 8762
Brownsville 2757
[[5]]
New York City-Manhattan
Battery Park 643283
Carnegie Hill 807204
Central Park 936840
Chelsea 4599098
Chinatown 211229
Clinton 2050545
[[6]]
New York City-Queens
Astoria-Long Island City 303231
Auburndale 464
Clearview 152
College Point 1
Corona 1496
Douglastown-Little Neck 937
[[7]]
New York City-Staten Island
Annandale 6
Ardon Heights 22
Bloomfield-Chelsea-Travis 26
Charlestown-Richmond Valley 7
Clifton 525
Ettingville 13
[[8]]
[1] Rochester
<0 rows> (or 0-length row.names)
[[9]]
[1] Syracuse
<0 rows> (or 0-length row.names)
이제 모델을 테스트 데이터에 적용하여 각 모델의 예측 성능을 비교할 수 있습니다. 의사 결정 트리 모델이 과다 적합(over-fitting)되어 만들어 진 것이 맞다면, 다른 두 모델과 비교하여 테스트 데이터에서도 예측 결과가 잘못 형성되는 것을 확인할 수 있어야 합니다. 랜덤 포리스트가 선형 모델에서는 누락되어 있는 데이터의 일부 고유 신호를 포착한다고 생각된다면, 테스트 데이터에서 선형 모델보다 성능이 우수한 모습을 확인할 수 있어야 합니다.
살펴볼 첫 번째 측정 기준은 제곱된 잔차의 평균(the average of the squared residuals)입니다. 이 값을 통하여 예측값이 관측값과 얼마나 가까운 지를 알 수 있습니다. 일반적으로 0% ~ 20%의 좁은 범위에 있는 팁 비율을 예측하기 때문에, 좋은 모델은 잔차가 평균 2 ~ 3 % 포인트를 넘지 않아야 할 것으로 예상해야 합니다.
rxPredict(trained.models$linmod, data = mht_split$test, outData = mht_split$test, predVarNames = "tip_percent_pred_linmod", overwrite = TRUE)
rxPredict(trained.models$dtree, data = mht_split$test, outData = mht_split$test, predVarNames = "tip_percent_pred_dtree", overwrite = TRUE)
rxPredict(trained.models$dforest, data = mht_split$test, outData = mht_split$test, predVarNames = "tip_percent_pred_dforest", overwrite = TRUE)
rxSummary(~ SE_linmod + SE_dtree + SE_dforest, data = mht_split$test,
transforms = list(SE_linmod = (tip_percent - tip_percent_pred_linmod)^2,
SE_dtree = (tip_percent - tip_percent_pred_dtree)^2,
SE_dforest = (tip_percent - tip_percent_pred_dforest)^2))
Call:
rxSummary(formula = ~ SE_linmod + SE_dtree + SE_dforest, data = mht_split$test,
transforms = list(SE_linmod = (tip_percent - tip_percent_pred_linmod)^2,
SE_dtree = (tip_percent - tip_percent_pred_dtree)^2,
SE_dforest = (tip_percent - tip_percent_pred_dforest)^2))
Summary Statistics Results for: ~SSE_linmod + SSE_dtree + SSE_dforest
Data: mht_split$test (RxXdfData Data Source)
File name: C:\Data\NYC_taxi\output\split\train.split.train.xdf
Number of valid observations: 43118543
Name Mean StdDev Min Max ValidObs MissingObs
SE_linmod 82.66458 108.9904 0.00000000005739206 9034.665 43118542 1
SE_dtree 82.40040 109.1038 0.00000251589457986 8940.693 43118542 1
SE_dforest 82.47107 108.0416 0.00000000001590368 8606.201 43118542 1
살펴볼 가치가 있는 또 다른 측정 기준은 상관 행렬(correlation matrix)입니다. 이는 서로 다른 모델의 예측이 어느 정도 서로 가깝고 어느 정도까지 실제 또는 관찰된 팁 비율에 근접하는지를 판단하는 데 도움이 될 수 있습니다.
rxc <- rxCor( ~ tip_percent + tip_percent_pred_linmod + tip_percent_pred_dtree + tip_percent_pred_dforest, data = mht_split$test)
print(rxc)
tip_percent pred_linmod pred_dtree pred_dforest
tip_percent 1.0000000 0.1391751 0.1500126 0.1499031
tip_percent_pred_linmod 0.1391751 1.0000000 0.8580617 0.9084119
tip_percent_pred_dtree 0.1500126 0.8580617 1.0000000 0.9404640
tip_percent_pred_dforest 0.1499031 0.9084119 0.9404640 1.0000000
예측 결과 비교
알고리즘을 테스트 데이터에 적용하기에 앞서서, 모든 범주형(categorical) 변수들의 조합으로 작은 데이터 세트에 알고리즘을 적용하고, 예측 결과를 시각화 합니다. 이것은 우리가 각각 알고리즘에 대한 직관을 발전시키는 것에 도움이 될 것입니다.
pred_df <- expand.grid(ll)
pred_df_1 <- rxPredict(trained.models$linmod, data = pred_df, predVarNames = "pred_linmod")
pred_df_2 <- rxPredict(trained.models$dtree, data = pred_df, predVarNames = "pred_dtree")
pred_df_3 <- rxPredict(trained.models$dforest, data = pred_df, predVarNames = "pred_dforest")
pred_df <- do.call(cbind, list(pred_df, pred_df_1, pred_df_2, pred_df_3))
head(pred_df)
pickup_nb dropoff_nb pickup_hour pickup_dow pred_linmod pred_dtree pred_dforest
1 Chinatown Chinatown 1AM-5AM Sun 6.869645 5.772054 9.008643
2 Little Italy Chinatown 1AM-5AM Sun 10.627190 9.221250 10.634590
3 Tribeca Chinatown 1AM-5AM Sun 9.063741 9.221250 10.099731
4 Soho Chinatown 1AM-5AM Sun 10.107815 8.313437 10.162946
5 Lower East Side Chinatown 1AM-5AM Sun 9.728399 9.221250 10.525242
6 Financial District Chinatown 1AM-5AM Sun 8.248997 6.937500 8.674807
observed_df <- rxSummary(tip_percent ~ pickup_nb:dropoff_nb:pickup_dow:pickup_hour, mht_xdf)
observed_df <- observed_df$categorical[[1]][ , c(2:6)]
pred_df <- inner_join(pred_df, observed_df, by = names(pred_df)[1:4])
ggplot(data = pred_df) +
geom_density(aes(x = Means, col = "observed average")) +
geom_density(aes(x = pred_linmod, col = "linmod")) +
geom_density(aes(x = pred_dtree, col = "dtree")) +
geom_density(aes(x = pred_dforest, col = "dforest")) +
xlim(-1, 30) +
xlab("tip percent")
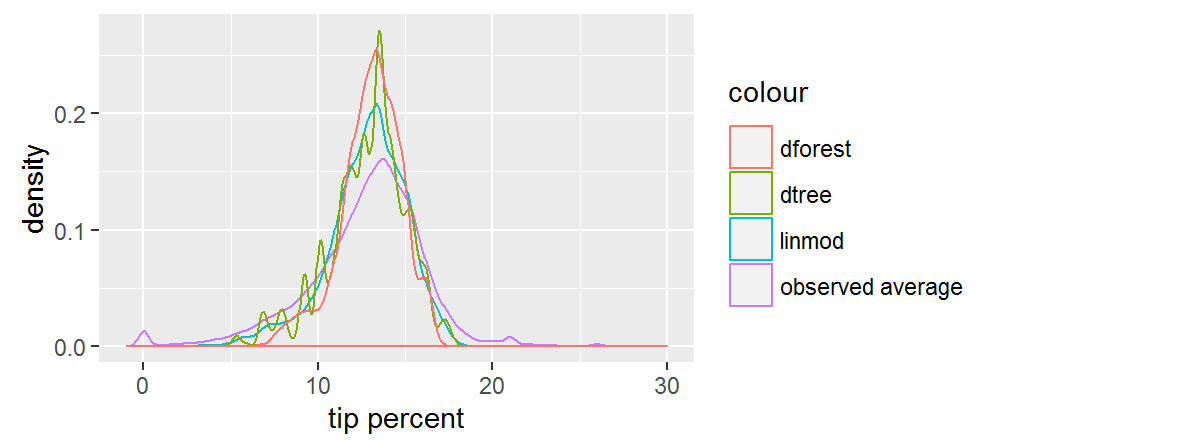
선형 모델과 랜덤 포레스트 모델은 둘 모두 우리에게 부드러운 곡선의 예측을 제공합니다. 우리는 랜덤 포레스트 예측이 가장 중앙 집중되어 있음을 알 수 있습니다. 의사 결정 트리에 대한 예측은 아마도 과다 적합(overfitting)의 결과로 인한 들쭉날쭉 한 분포를 따르지만, 우리가 테스트 세트에 대하여 성능을 확인하기 이전까지는 정말 이런 모습인지를 알 수 없습니다. 전체적으로, 예측 결과들은 측정된 평균보다 폭이 더 좁습니다.