예측 결과 비교
알고리즘을 테스트 데이터에 적용하기에 앞서서, 모든 범주형(categorical) 변수들의 조합으로 작은 데이터 세트에 알고리즘을 적용하고, 예측 결과를 시각화 합니다. 이것은 우리가 각각 알고리즘에 대한 직관을 발전시키는 것에 도움이 될 것입니다.
pred_df <- expand.grid(ll)
pred_df_1 <- rxPredict(trained.models$linmod, data = pred_df, predVarNames = "pred_linmod")
pred_df_2 <- rxPredict(trained.models$dtree, data = pred_df, predVarNames = "pred_dtree")
pred_df_3 <- rxPredict(trained.models$dforest, data = pred_df, predVarNames = "pred_dforest")
pred_df <- do.call(cbind, list(pred_df, pred_df_1, pred_df_2, pred_df_3))
head(pred_df)
pickup_nb dropoff_nb pickup_hour pickup_dow pred_linmod pred_dtree pred_dforest
1 Chinatown Chinatown 1AM-5AM Sun 6.869645 5.772054 9.008643
2 Little Italy Chinatown 1AM-5AM Sun 10.627190 9.221250 10.634590
3 Tribeca Chinatown 1AM-5AM Sun 9.063741 9.221250 10.099731
4 Soho Chinatown 1AM-5AM Sun 10.107815 8.313437 10.162946
5 Lower East Side Chinatown 1AM-5AM Sun 9.728399 9.221250 10.525242
6 Financial District Chinatown 1AM-5AM Sun 8.248997 6.937500 8.674807
observed_df <- rxSummary(tip_percent ~ pickup_nb:dropoff_nb:pickup_dow:pickup_hour, mht_xdf)
observed_df <- observed_df$categorical[[1]][ , c(2:6)]
pred_df <- inner_join(pred_df, observed_df, by = names(pred_df)[1:4])
ggplot(data = pred_df) +
geom_density(aes(x = Means, col = "observed average")) +
geom_density(aes(x = pred_linmod, col = "linmod")) +
geom_density(aes(x = pred_dtree, col = "dtree")) +
geom_density(aes(x = pred_dforest, col = "dforest")) +
xlim(-1, 30) +
xlab("tip percent")
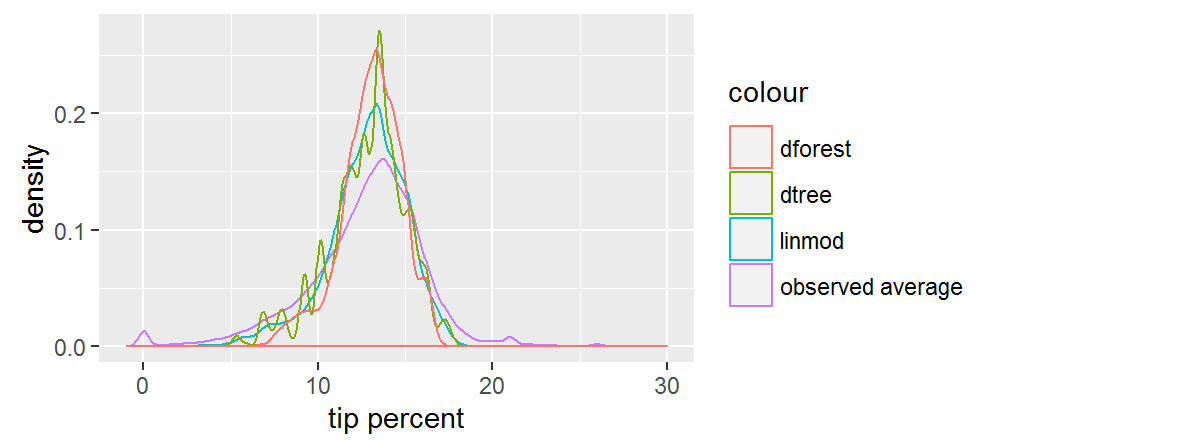
선형 모델과 ��덤 포레스트 모델은 둘 모두 우리에게 부드러운 곡선의 예측을 제공합니다. 우리는 랜덤 포레스트 예측이 가장 중앙 집중되어 있음을 알 수 있습니다. 의사 결정 트리에 대한 예측은 아마도 과다 적합(overfitting)의 결과로 인한 들쭉날쭉 한 분포를 따르지만, 우리가 테스트 세트에 대하여 성능을 확인하기 이전까지는 정말 이런 모습인지를 알 수 없습니다. 전체적으로, 예측 결과들은 측정된 평균보다 폭이 더 좁습니다.