지역(neighborhoods) 조사
"~ ." 파라미터를 rxSummary 함수에 전달하여, 데이터 상의 모든 컬럼에 대한 요약 정보를 얻을 수 있습니다.
system.time(
rxs_all <- rxSummary( ~ ., nyc_xdf)
)
Rows Processed: 69406520
user system elapsed
0.05 0.02 85.16
예를 들자면, 데이터에서 숫자와 관련된 열에 대한 요약은 rxs_all의 sDataFrame이라는 항목 아래의 저장됩니다.
Name Mean StdDev Min Max ValidObs
1 VendorID NA NA NA NA 69406520
2 tpep_pickup_datetime NA NA NA NA 0
3 tpep_dropoff_datetime NA NA NA NA 0
4 passenger_count 1.660674 1.310478 0.0000 9.0000 69406520
5 trip_distance 4.850022 4044.503422 -3390583.8000 19072628.8000 69406520
6 pickup_longitude -72.920469 8.763351 -165.0819 118.4089 69406520
MissingObs
1 0
2 0
3 0
4 0
5 0
6 0
만약 우리가 데이터의 각 factor 열에 대한 level 수를 보여 주는 단방향 테이블을 원한다면, rxs_all을 참조하여 얻을 수 있지만, 특정 factor 열과 다른 factor열의 조합 별로 집계한 수를 보여주는 두방향의 테이블을 보려고 한다면, 올바른 수식을 요약 함수에 전달하는 것이 필요합니다. 여기에서는 rxCrossTabs 함수를 사용하여 한 지역에서 다른 지역으로 이동하는 횟수를 구합니다.
nhoods_by_borough <- rxCrossTabs( ~ pickup_nhood:pickup_borough, nyc_xdf)
nhoods_by_borough <- nhoods_by_borough$counts[[1]]
nhoods_by_borough <- as.data.frame(nhoods_by_borough)
# get the neighborhoods by borough
lnbs <- lapply(names(nhoods_by_borough), function(vv) subset(nhoods_by_borough, nhoods_by_borough[ , vv] > 0, select = vv, drop = FALSE))
lapply(lnbs, head)
[[1]]
[1] Albany
<0 rows> (or 0-length row.names)
[[2]]
[1] Buffalo
<0 rows> (or 0-length row.names)
[[3]]
New York City-Bronx
Baychester 125
Bedford Park 1413
City Island 52
Country Club 354
Eastchester 98
Fordham 1243
[[4]]
New York City-Brooklyn
Bay Ridge 3378
Bedford-Stuyvesant 54269
Bensonhurst 1159
Boerum Hill 76404
Borough Park 8762
Brownsville 2757
[[5]]
New York City-Manhattan
Battery Park 643283
Carnegie Hill 807204
Central Park 936840
Chelsea 4599098
Chinatown 211229
Clinton 2050545
[[6]]
New York City-Queens
Astoria-Long Island City 303231
Auburndale 464
Clearview 152
College Point 1
Corona 1496
Douglastown-Little Neck 937
[[7]]
New York City-Staten Island
Annandale 6
Ardon Heights 22
Bloomfield-Chelsea-Travis 26
Charlestown-Richmond Valley 7
Clifton 525
Ettingville 13
[[8]]
[1] Rochester
<0 rows> (or 0-length row.names)
[[9]]
[1] Syracuse
<0 rows> (or 0-length row.names)
지역간 전체 및 한계 운행 분포(Total and marginal distribution trips)
이제 다음과 같은 중요한 질문에 주의를 집중해 보겠습니다.
- 일반적으로 어느 지역 사이에서 가장 운행이 활발하게 이루어지는가?
- 여행자가 특정 지역에서 출발할 경우, 가장 목적지가 되기 쉬운 지역은 어디인가?
- 특정 지역에 누군가가 방금 하차하였다면, 출발지로 가장 ��력한 곳은 어느 지역인가?
위의 질문에 답하기 위해, 우리는 두 개 지역 사이의 운행 분포(또는 비율) 정보가 필요하며, 이는 먼저 전체 여행에 대한 백분율로, 다음으로 특정 이웃에서 출발하는 운행에 대한 백분율로, 마지막으로 특정 지역의 도착에 대한 백분율로서 계산되어야 합니다.
rxc <- rxCube( ~ pickup_nb:dropoff_nb, mht_xdf)
rxc <- as.data.frame(rxc)
library(dplyr)
rxc %>%
filter(Counts > 0) %>%
mutate(pct_all = Counts/sum(Counts) * 100) %>%
group_by(pickup_nb) %>%
mutate(pct_by_pickup_nb = Counts/sum(Counts) * 100) %>%
group_by(dropoff_nb) %>%
mutate(pct_by_dropoff_nb = Counts/sum(Counts) * 100) %>%
group_by() %>%
arrange(desc(Counts)) -> rxcs
head(rxcs)
# A tibble: 6 × 6
pickup_nb dropoff_nb Counts pct_all pct_by_pickup_nb
<fctr> <fctr> <dbl> <dbl> <dbl>
1 Upper East Side Upper East Side 3299324 5.738650 36.88840
2 Midtown Midtown 2216184 3.854700 21.84268
3 Upper West Side Upper West Side 1924205 3.346849 35.14494
4 Midtown Upper East Side 1646843 2.864422 16.23127
5 Upper East Side Midtown 1607925 2.796730 17.97756
6 Garment District Midtown 1072732 1.865847 28.94205
pct_by_dropoff_nb
<dbl>
1 38.28066
2 22.41298
3 35.15770
4 19.10762
5 16.26146
6 10.84888
첫 번째 행을 기준으로 볼 때, Upper East Side에서 Upper East Side 로의 운행이 맨해튼의 모든 택시 운행의 약 5 %를 차지한다는 것을 알 수 있습니다. Upper East Side에서 출발하는 모든 여행 중 약 36 %가 Upper East Side에서 하차합니다. Upper East Side에 도착하는 모든 여행 중 37 %가 또한 Upper East Side에서 출발한 것으로 나타났습니다.
지역 리팩토링
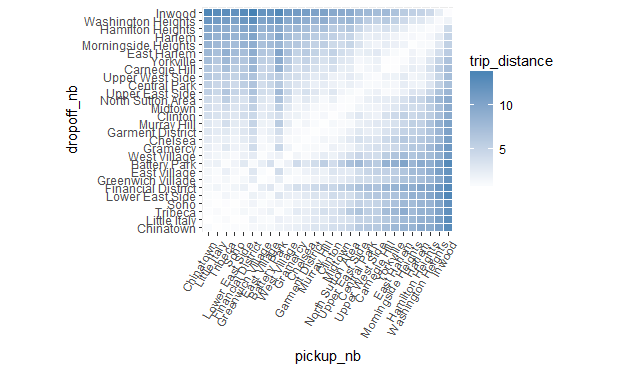
plot 챠트에서 보이는 것처럼, 서로 가까이 있는 지역 사이에서 많은 트래픽이 발생합니다. 멀리 떨어져 있는 지역 간의 운행의 경우, 시내 중심을 통과할 경우 발생하는 대부분의 트래픽을 주변의 우회 경로를 사용하여 피할 수 있기 때문에, 이러한 결과는 그리 놀라운 일이 아닙니다. 우리는 또한 일반적으로 미드 타운(midtown) 지역과 도심(downtown), 특히 차이나타운(Chinatown)과 리틀 이태리(Little Italy) 사이에서 높은 트래픽을 볼 수 있습니다.
위의 챠트를 그리기 위해서, pickup_nb 및 dropoff_nb에 대한 factor의 level 순서를 변경했습니다. 이러한 순서 변경은 데이터 자체에서 발생하는 것이 바람직 합니다. 그렇지 않으면 pickup_nb 또는 dropoff_nb와 관련된 챠트를 생성할 때마다 factor의 level 순서를 매번 변경해야만 합니다. 이제 순서를 변경하고 이 내용을 전체 데이터에 적용해 보겠습니다. 변경을 위한 다음 두 가지 옵션이 있습니다.
- rxDataStep을 transforms 인수와 함께 사용하고, Base R 함수 factor를 사용하여 factor의 level 순서를 바꿀 수 있습니다.
- rxFactor 함수와 factorInfo를 사용하여 factor의 level을 조작할 수 있습니다. rxFactors는 메타 데이터 수준에서 작동하기 때문에 더 빠르다는 장점이 있습니다. 단점은 Hadoop이나 Spark와 같은 다른 계산 컨텍스트에서는 작동하지 않을 수 있다는 것입니다.
두 가지 방법 모두 아래에서 보실 수 있습니다.
# factor의 level 순서를 바꾸기 위한 첫 번째 방법
rxDataStep(inData = mht_xdf, outFile = mht_xdf,
transforms = list(pickup_nb = factor(pickup_nb, levels = newlevels),
dropoff_nb = factor(dropoff_nb, levels = newlevels)),
transformObjects = list(newlevels = unique(newlevs)),
overwrite = TRUE)
# factor의 level 순서를 바꾸기 위한 두 번째 방법
rxFactors(mht_xdf, outFile = mht_xdf, factorInfo = list(pickup_nb = list(newLevels = unique(newlevs)), dropoff_nb = list(newLevels = unique(newlevs))), overwrite = TRUE)
지역 순서 재조정
다음 단계의 작업으로, 승차 및 하차 지역과 요금, 여행 거리, 교통량 및 팁과 같은 다른 변수 사이의 패턴을 찾아 보겠습니다. 교통량(traffic)이 운행 시간이 예상보다 오래 걸리게 하는 가장 일반적인 이유라고 가정하에, 주행 기간과 거리의 비율을 보고 교통량(traffic)을 추정합니다.
이 분석을 위해 우리는 rxCube와 rxCrossTabs을 사용합니다. 둘 다 rxSummary와 매우 유사하지만 더 적은 통계 요약을 반환하므로 더 빠르게 실행됩니다. y ~ u:v를 수식으로 사용하면, rxCrossTabs는 총수와 합계를 반환하고, rxCube는 열 u와 v의 조합으로 나누어 진 열 y의 총수와 평균을 반환합니다. 두 함수의 또 다른 중요한 차이점은 rxCrossTabs는 배열을 반환하지만 rxCube data.frame을 반환한다는 점입니다. 문제를 어떻게 해결 하려는지에 따라, 우리는 둘 중 하나를 선택할 수 있습니다(물론 "다시 모양을 바꾸어" 서로 결과 형식을 변환할 수는 있지만, 이는 추가 작업이 필요합니다).
실제로 이것이 무엇을 의미하는지 보겠습니다. rxCrossTabs를 사용하여 trip_distance에 대한 합계와 총수를 얻고, pickup_nb와 dropoff_nb로 나눈다. 평균을 얻기 위해 합계를 총수로 바로 나눌 수 있습니다. 그 결과를 주행 거리 행렬(distance matrix)이라고 부르며, seriation 라이브러리의 seriate 함수에 입력하여, 가까운 지역들이 서로 인접하여 나타나게 할 수 있습니다(현재는 알파벳순으로 정렬되어 있으며, 이는 R에서 별도 지정되지 않은 경우 기본적으로 사용하는 factor의 level 정렬 순서 입니다).
rxct <- rxCrossTabs(trip_distance ~ pickup_nb:dropoff_nb, mht_xdf)
res <- rxct$sums$trip_distance / rxct$counts$trip_distance
library(seriation)
res[which(is.nan(res))] <- mean(res, na.rm = TRUE)
nb_order <- seriate(res)
잠시 후 nb_order를 사용할 것입니다. 그렇지만 먼저 rxCube를 사용하여 trip_distance에 대한 총수와 평균, 운행시 마일당 택시에서 보내는 시간을 나타내는 새로운 데이터 포인트와 tip_percent를 얻도록 하겠습니다. 위의 예제에서, 우리는 반환 객체로 행렬을 원했기 때문에, rxCrossTabs를 사용했기 때문에, 결과를 seriate로 전달할 수 있었습니다. 이번에는 ggplot2를 사용하여 플로팅하는 데 사용할 계획이기 때문에, rxCube를 사용하여 data.frame을 얻도록 합니다. ggplot2에서는 긴 data.frame을 입력으로 사용하는 것이 넓은 matirx를 쓰는 것과 비교했을 때 더 코딩하기가 쉽습니다.
rxc1 <- rxCube(trip_distance ~ pickup_nb:dropoff_nb, mht_xdf)
rxc2 <- rxCube(minutes_per_mile ~ pickup_nb:dropoff_nb, mht_xdf,
transforms = list(minutes_per_mile = (trip_duration/60)/trip_distance))
rxc3 <- rxCube(tip_percent ~ pickup_nb:dropoff_nb, mht_xdf)
res <- bind_cols(list(rxc1, rxc2, rxc3))
res <- res[ , c('pickup_nb', 'dropoff_nb', 'trip_distance', 'minutes_per_mile', 'tip_percent')]
head(res)
# A tibble: 6 × 5
pickup_nb dropoff_nb trip_distance minutes_per_mile tip_percent
<fctr> <fctr> <dbl> <dbl> <dbl>
1 Battery Park Battery Park 1.015857 11.579629 11.394900
2 Carnegie Hill Battery Park 8.570623 3.944350 12.391030
3 Central Park Battery Park 6.277666 5.243241 10.326531
4 Chelsea Battery Park 2.995946 5.169887 11.992151
5 Chinatown Battery Park 1.771597 9.001305 10.292683
6 Clinton Battery Park 3.993806 4.839858 9.794098
위의 결과를 plotting하여 보다 흥미로운 추세를 볼 수 있습니다.
library(ggplot2)
ggplot(res, aes(pickup_nb, dropoff_nb)) +
geom_tile(aes(fill = trip_distance), colour = "white") +
theme(axis.text.x = element_text(angle = 60, hjust = 1)) +
scale_fill_gradient(low = "white", high = "steelblue") +
coord_fixed(ratio = .9)

위의 polt 챠트의 문제는, 지역의 순서 (알파벳 순서)로, 챠트의 내용을 다소 임의적이며 쓸모 없도록 만들어 버립니다. 그러나 위에서 언급하였듯이 seriate 함수를 사용하여 지역에 대하여 보다 자연스러운 정렬 순서를 찾았으므로, 이를 사용하여 위의 챠트를 보다 적합한 방식으로 재정렬 할 수 있습니다. plot에서 지역의 순서를 바꾸려면, nb_order에 주어진 순서대로 factor의 level에 대한 정렬을 바꾸면됩니다.
newlevs <- levels(res$pickup_nb)[unlist(nb_order)]
res$pickup_nb <- factor(res$pickup_nb, levels = unique(newlevs))
res$dropoff_nb <- factor(res$dropoff_nb, levels = unique(newlevs))
library(ggplot2)
ggplot(res, aes(pickup_nb, dropoff_nb)) +
geom_tile(aes(fill = trip_distance), colour = "white") +
theme(axis.text.x = element_text(angle = 60, hjust = 1)) +
scale_fill_gradient(low = "white", high = "steelblue") +
coord_fixed(ratio = .9)
데이터 시각화
데이터 시각화는 데이터를 잘 이해하는데 유용합니다. 분석을 위해 데이터를 준비하기 위해 수행하기 위해 필요한 작업들을 예상하기 위한 좋은 방법일 수 있습니다. 시각화는 너무 많은 숫자를 보여 주지 않으면서 우리의 결과를 제시하는 좋은 방법이 될 수 있습니다.
대부분의 시각화에서, 큰 데이터 세트는 어떠한 것이든 문제를 초래할 수 있습니다. 예를 들어, scatter plot에 너무 많은 데이터 항목이 있는 경우, 너무 복잡해지기 때문에 데이터를 추세를 볼 수가 없습니다. 너무 많은 포인트는 시각화를 처리하는 데 너무 많은 시간이 걸립니다. 히스토그램 이나 막대 그래프 같은 다른 일부 시각화는 더 많은 데이터를 처리하는 데에도 그다지 오랜 시간이 걸리지 않습니다. 이것이 RevoScaleR에 rxHistogram 함수가 존재하지만, scatter plots에 대한 함수가 필요 없게된 이유입니다.
그러므로 대규모 데이터 세트를 처리할 때에는, 원시 데이터 대신 집계 된 데이터에 대하여 시각화를 만드는 것이 훨씬 더 일반적 입니다. 우리는 이번 과정에서 몇 가지 예제를 보게 될 것입니다. 일단 데이터가 집계되면, ggplot2와 같은 도구에 대하여 약간의 데이터 재구성을 통해 준비하여 시각화된 결과를 표시 할 수 있습니다.
맨해튼으로 필터링
우리는 이제 맨하탄 내에서만 일어난 운행에 대해서 만으로 초점을 맞춤으로써 분석 범위를 좁히어, 운행에 대한 "합리적인" 기준을 수립하도록 합니다. 데이터에 새로운 특성들을 추가하였으므로, 데이터에서 이제는 필요 없는 예전의 열들을 삭제하여 데이터가 더 빨리 처리되도록 할 수 있습니다.
input_xdf <- 'yellow_tripdata_2016_manhattan.xdf'
mht_xdf <- RxXdfData(input_xdf)
rxDataStep(nyc_xdf, mht_xdf,
rowSelection = (
passenger_count > 0 &
trip_distance >= 0 & trip_distance < 30 &
trip_duration > 0 & trip_duration < 60*60*24 &
str_detect(pickup_borough, 'Manhattan') &
str_detect(dropoff_borough, 'Manhattan') &
!is.na(pickup_nb) &
!is.na(dropoff_nb) &
fare_amount > 0),
transformPackages = "stringr",
varsToDrop = c('extra', 'mta_tax', 'improvement_surcharge', 'total_amount',
'pickup_borough', 'dropoff_borough', 'pickup_nhood', 'dropoff_nhood'),
overwrite = TRUE)
그리고 우리가 데이터의 범위를 제한하였기 때문에, 새로운 데이터 샘플을 data.frame으로 작성하는 것이 좋습니다. 마지막 샘플이었던 nyc_sample_df는 데이터의 최초 1000 개 행만 가져 왔기 때문에 그다지 좋은 샘플이 아니었습니다. 이번에는 rxDataStep을 사용하여 더 큰 데이터 집합으로 부터 전체 행의 1% 만 포함하는 임의의 데이터 샘플을 만듭니다.
mht_sample_df <- rxDataStep(mht_xdf, rowSelection = (u < .01),
transforms = list(u = runif(.rxNumRows)))
dim(mht_sample_df)
Rows Processed: 57493035
WARNING: The number of rows (574832) times the number of columns (24)
exceeds the 'maxRowsByCols' argument (3000000). Rows will be truncated.
> dim(mht_sample_df)
[1] 125000 24
이상값 조사
RevoScaleR을 사용하여 이상치에 대한 데이터를 검사하는 방법을 살펴 보겠습니다. 여기서의 우리 접근 방식은 다소 원시적인 것이지만, 이는 도구를 사용하는 방법을 보여주기 위한 것입니다. rxDataStep 및 rowSelection 인수를 사용하여 이상값 후보가 될 모든 데이터 요소를 추출합니다. outFile 인수를 빈 값으로 설정하여, 결과 데이터 집합을 odd_trips라는 이름의 data.frame으로 출력합니다. 마지막으로, 우리가 아웃 라이어 선택 기준을 너무 넓게 잡았을 경우에는 결과인 data.frame에 지나치게 많은 행이 존재할 수 있습니다(이는 메모리상에 문제를 발생키시고 플롯 작성 및 기타 요약을 생성하는 속도를 느리게 함). 따라서 새로운 열 u를 만들고 0에서 1 사이의 임의의 균일하게 분포된 숫자를 채우도록 한 다음, rowSelection 조건에 u <.05를 추가합니다. 이 숫자를 조정하여 더 작은 data.frame(0에 가까운 기준값) 또는 더 큰 data.frame (1에 가까운 기준값)으로 데이터 사이즈를 조정할 수 있습니다.
# outFile argument missing means we output to data.frame
odd_trips <- rxDataStep(nyc_xdf, rowSelection = (
u < .05 & ( # we can adjust this if the data gets too big
(trip_distance > 50 | trip_distance <= 0) |
(passenger_count > 5 | passenger_count == 0) |
(fare_amount > 5000 | fare_amount <= 0)
)), transforms = list(u = runif(.rxNumRows)))
print(dim(odd_trips))
[1] 93750 32
이상값 후보들을 가진 데이터 집합은 data.frame이기 때문에, Base R의 어떤 함수로도 이를 검사 할 수 있습니다. 예를 들어, odd_trips를 50 마일을 초과하는 거리로만 제한하고, 승객이 지불한 운임의 히스토그램을 그리고, 여행에 10 분 이상 걸렸는지 아닌지에 따라 색상을 지정합니다.
odd_trips %>%
filter(trip_distance > 50) %>%
ggplot() -> p
p + geom_histogram(aes(x = fare_amount, fill = trip_duration <= 10*60), binwidth = 10) +
xlim(0, 500) + coord_fixed(ratio = 25)
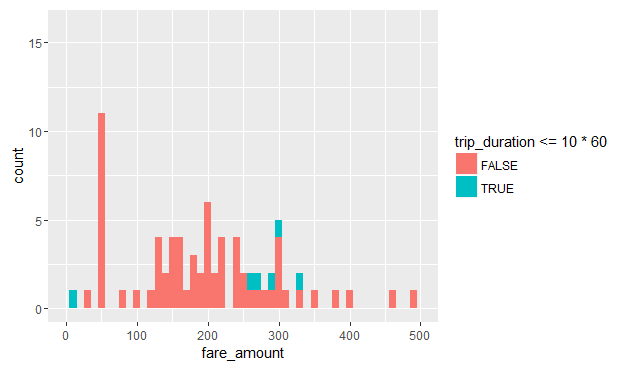
보시는 것처럼, 대다수의 50 마일 이상의 주행거리 건들이, 대부분 10분 이상 운행되었음에도, 비용이 없거나 거의 들지 않았습니다. 이러한 운행 데이터가 기계의 오류인지 또는 사람의 실수로 인한 것인지 여부는 확실하지 않지만, 예를 들어 이 분석이 택시를 소유한 특정 회사를 대상으로 할 경우라면, 이를 확인하기 위하여 더 많은 조사가 아마도 이어서 진행될 것입니다.
운행 거리 조사
데이터는 보통 지저분 하기 때문에 일을 처리 하기에 앞서서 정제를 해야하는 경우가 많습니다. 데이터에 대한 요약 및 스냅 샷에 대한 작업을 살퍼보면서, 데이터를 어떻게 정리해야 하는지 알 수 있습니다. 다음은 몇 가지 제안 사항입니다.
- 누락된 값들이 제대로 반영 되었습니까? 플랫 파일에서 누락값은 종종 NA 와는 다르게 표현됩니다. 예를 들어, 누락된 숫자열이 빈 셀이나 NULL 또는 999를 사용하여 표현되는 것처럼, 문자열의 누락된 값은 빈 항목이나 '기타' 또는 'n/a'와 같은 포괄적인 용어로 표현되어 있는 셀을 가질 수 있습니다. 또는 보다 상세한 누락값에 대한 구분을 표시하기 위해 다른 코드가 사용될 수도 있습니다(정보가 관련이 없기 때문에 누락 또는 데이터 또는 정보가 제공되지 않았기 때문에 누락 등). R에서 누락된 값을 기록하기 위하여 NA를 사요할 때에는 이러한 차이를 고려하는 것이 중요합니다.
- 열 유형이 예상과 일치합니까? 이것은 중요한 고려 사항이며, 데이터를 읽기 전에 명시적으로 열 유형을 제공함으로써 이를 관리하여야 합니다. 이는 불필요한 처리, 특히 R이 필요하지 않을 때 factor로 열에서 읽는 경우 발생하는 처리를 피하기 때문에 선호되는 방법입니다. factor로 지정된 높은 카디널리티가 있는 열은 R 세션에 많은 오버 헤드를 주게 됩니다. 이러한 열은 보통 factor일 필요가 없으며, 정수 또는 문자열로 남아 있어야만 합니다. 어떤 열이 factor가 되어야 하는지 어떤 열이 아닌지를 미리 알지 못하거나, 열을 factor로 변환하기 전에 정제를 할 필요가 있는 경우, rxImport를 실행 시에 stringsAsFactors = FALSE로 설정하거나 숫자가 아닌 모든 열을 문자 열로 지정하여 문자열을 factor로 자동 변환되는 것을 억제 할 수 있습니다.
- 데이터에 이상값이 존재하고 있고 이 값이 타당하게 보입니까? 흔히 이상값인지 아닌지에 대한 문제는 우리가 데이터에 대하여 얼마나 이해하고 있는지, 데이터의 평균 패턴과의 편차에 대하여 얼마나 허용할 것인지에 달려 있습니다. 뉴욕 택시 데이터 세트에서는 다음과 같은 경우들이 고려되어야 합니다. (1) 승객이 택시를 타고 하루 종일 타고 다니면서 운전 기사에게 기다리라고 요청하면서 여러 용무를 보는 경우가 있을 수 있습니다. (2) 승객이 40 달러의 운행 요금에 대하여 5 달러를 팁으로 주려다가 실수로 5 번을 두 번 누르고 55 달러를 지불할 수 있습니다. (3) 승객은 운전자와 다투고는 요금을 지불하지 않고 떠날 수 있습니다. (4) 여러 건의 운행에 대하여 특정한 한 사람이 비용을 지불하거나, 한 건의 운행에 대하여 여러 명이 각자 자기 요금많을 지불할 수 있습니다. 이 때, 어떤 사람은 카드로 또 어떤 사람은 현금으로 지불합니다. (5) 운전자는 승객이 하차한 이후에도 우발적으로 거리계를 계속 작동시키고 있을 수 있습니다. (6) 기계의 오류로 인해 기록된 데이터가 없거나 잘못된 데이터가 발생할 수 있습니다. 이 모든 경우에 있어서, 우리가 쉽게 이러한 활동들을 포착할 수 있다고 가정하더라도(데이터 포인트들의 조합 일부가 비정상적인 범위 내에 있기 때문에), 이러한 값이 타당한지에 대한 부분은 우리가 분석하고자 하는 목적이 무엇인지에 달려 있습니다. 이상값 하나는 어떤 분석에서는 잡음이 되지만 다른 분석에는서 관심을 가져야 하는 흥미로운 지점일 수 있는 것입니다.
이제 특이값 후보치를 가진 데이터를 얻었으므로 특정 패턴을 조사해 볼 수 있습니다. 예를 들어, trip_distance의 히스토그램을 그릴 수 있고 대다수는 5 마일 미만으로 거의 모든 여행이 20 마일 미만의 거리를 여행했다는 것을 알 수 있습니다. .
rxHistogram( ~ trip_distance, nyc_xdf, startVal = 0, endVal = 25, histType = "Percent", numBreaks = 20)
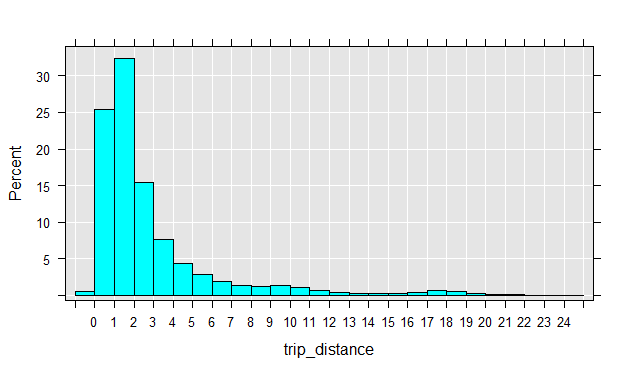
16과 20마일 사이의 주행 거리에서 두 번째 피크가 있으며, 이는 좀 더 살펴볼 필요가 있습니다. 우리는 승객이 어느 지역에서 어느 지역으로 이동하는 지를 조사함으로써 이것을 확인할 수 있습니다.
rxs <- rxSummary( ~ pickup_nhood:dropoff_nhood, nyc_xdf, rowSelection = (trip_distance > 15 & trip_distance < 22))
head(arrange(rxs$categorical[[1]], desc(Counts)), 10)
pickup_nhood dropoff_nhood Counts
1 Midtown Gravesend-Sheepshead Bay 2517
2 Upper East Side Gravesend-Sheepshead Bay 1090
3 Midtown Douglastown-Little Neck 1013
4 Midtown Midtown 978
5 Garment District Gravesend-Sheepshead Bay 911
6 Midtown Bensonhurst 878
7 Gramercy Gravesend-Sheepshead Bay 784
8 Jamaica Upper West Side 775
9 Chelsea Gravesend-Sheepshead Bay 729
10 Midtown Bay Ridge 687
보이는 것처럼, Gravesend-Sheepshead Bay는 목적지로 자주 보이며, 놀랍게도, 탑승 포인트로는 아닌 것으로 나타납니다. 또한 JFK 공항과 가장 가까운 지역인 Jamaica에서 출발하거나, 도착하는 주행 기록들을 볼 수 있습니다.
맨해튼 지역에 집중
택시 운행의 가장 많은 부분이 맨해튼에서 이루어지기 때문에, 우리는 맨해튼에 집중하고 다른 네 개의 지역은 무시합니다. 이를 위해 pickup_nhood 및 dropoff_nb 라는 원래 열을 기반으로 두 개의 새 열인 pickup_nhood 및 dropoff_nhood를 만듭니다. 단 factor의 level은 맨해튼 지역으로 제한합니다 (다른 factor level은 NA로 대체 됨). 이렇게 하지 않으면 맨해튼 외부의 다른 지역이 해당 열과 관련된 모델링 또는 요약 함수에 표시되기 때문에, 이렇게 처리하는 것이 중요합니다.
manhattan_nhoods <- rownames(nhoods_by_borough)[nhoods_by_borough$`New York City-Manhattan` > 0]
refactor_columns <- function(dataList) {
dataList$pickup_nb = factor(dataList$pickup_nhood, levels = nhoods_levels)
dataList$dropoff_nb = factor(dataList$dropoff_nhood, levels = nhoods_levels)
dataList
}
rxDataStep(nyc_xdf, nyc_xdf,
transformFunc = refactor_columns,
transformObjects = list(nhoods_levels = manhattan_nhoods),
overwrite = TRUE)
rxs_pickdrop <- rxSummary( ~ pickup_nb:dropoff_nb, nyc_xdf)
head(rxs_pickdrop$categorical[[1]])
Rows Processed: 69406520
pickup_nb dropoff_nb Counts
1 Battery Park Battery Park 19876
2 Carnegie Hill Battery Park 2699
3 Central Park Battery Park 3479
4 Chelsea Battery Park 61024
5 Chinatown Battery Park 3813
6 Clinton Battery Park 23962
데이터 조사
데이터가 논리적 관점에서 합리적인지를 묻는 것에 더하여, 데이터가 비즈니스 관점 또는 실질적인 관점에서 합당한 지를 확인하는 것이 좋습니다. 이러한 검토를 통하여 데이터에 잘못된 라벨이 지정되거나 잘못된 기능 집합을 갖도록 하는 속성과 같은 데이터의 특정한 오류를 발견하는 데 도움이 됩니다. 내용들이 규명되지 않을 경우, 이러한 작은 오류들이 분석에 큰 영향을 미칠 수 있습니다.
학습 목표
이 장을 학습한 후, 우리는 다음과 같은 방법들을 알게 될 것입니다.
- 데이터에 대한 기본 도표 작성 및 요약을 실행합니다.
- RevoScaleR summary 함수에서 반환 객체를 가져 와서 R 함수를 사용하여 플로팅 및 추가 처리를 수행합니다.
- rxHistogram을 사용하여 열의 분포를 시각화합니다.
- 큰 데이터의 무작위 표본을 추출하고 이를 이용하여 이상값을 검사합니다.