새로운 열 조사
변환이 어느 정도 효과가 있었는지를 확인하기 위해, 만들어진 새로운 열을 살펴 보겠습니다. 우리는 rxSummary 함수를 사용하여 데이터의 통계적 요약을 얻습니다. rxSummary 함수는 기본 R에있는 Summary 함수와 비슷하며 두 가지 방법으로 작동됩니다 (Summary 함수는 data.frame에서만 작동)
- 숫자 열에 대한 수치 요약을 제공합니다 (백분위 수 제외, 여기에는 rxQuantile 함수를 사용함).
- factor 열의 각 수준에 대해 합계값을 제공합니다.
우리는 다른 많은 R 모델링 또는 플로팅 함수에서 사용하는 것과 동일한 수식 표기법을 사용하여 요약할 열을 지정합니다. 예를 들어 아래에서는 pickup_hour 및 pickup_dow (둘 모두 factor)와 trip_duration (숫자, 초 단위)의 요약을 보려고 합니다.
rxs1 <- rxSummary( ~ pickup_hour + pickup_dow + trip_duration, nyc_xdf)
# 합계 숫자 옆에 비율에 대한 열을 추가 할 수 있습니다.
rxs1$categorical <- lapply(rxs1$categorical, function(x) cbind(x, prop = round(prop.table(x$Counts), 2)))
rxs1
Call:
rxSummary(formula = ~pickup_hour + pickup_dow + trip_duration,
data = nyc_xdf)
Summary Statistics Results for: ~pickup_hour + pickup_dow + trip_duration
Data: nyc_xdf (RxXdfData Data Source)
File name: yellow_tripdata_2016.xdf
Number of valid observations: 69406520
Name Mean StdDev Min Max ValidObs MissingObs
trip_duration 933.9168 119243.5 -631148790 11538803 69406520 0
Category Counts for pickup_hour
Number of categories: 7
Number of valid observations: 69406520
Number of missing observations: 0
pickup_hour Counts prop
1AM-5AM 3801430 0.05
5AM-9AM 10630653 0.15
9AM-12PM 9765429 0.14
12PM-4PM 13473045 0.19
4PM-6PM 7946899 0.11
6PM-10PM 16138968 0.23
10PM-1AM 7650096 0.11
Category Counts for pickup_dow
Number of categories: 7
Number of valid observations: 69406520
Number of missing observations: 0
pickup_dow Counts prop
Sun 9267881 0.13
Mon 8938785 0.13
Tue 9667525 0.14
Wed 9982769 0.14
Thu 10398738 0.15
Fri 10655022 0.15
Sat 10495800 0.15
플러스 기호 (pickup_dow + pickup_hour) 대신 콜론 (pickup_dow : pickup_hour)으로 두 변수를 구분하면 개별 컬럼 대신 두 개의 인수 facor 열의 수준(level) 별로 각 조합에 대한 요약을 얻을 수 있습니다.
rxs2 <- rxSummary( ~ pickup_dow:pickup_hour, nyc_xdf)
rxs2 <- tidyr::spread(rxs2$categorical[[1]], key = 'pickup_hour', value = 'Counts')
row.names(rxs2) <- rxs2[ , 1]
rxs2 <- as.matrix(rxs2[ , -1])
rxs2
1AM-5AM 5AM-9AM 9AM-12PM 12PM-4PM 4PM-6PM 6PM-10PM 10PM-1AM
Sun 1040233 740157 1396409 1980752 1032434 1697529 1380367
Mon 304474 1630951 1268326 1838143 1133728 2096219 666944
Tue 278407 1840134 1382381 1882356 1151837 2390506 741904
Wed 313809 1854757 1417953 1880896 1142071 2508618 864665
Thu 354646 1871828 1428985 1922502 1165535 2634023 1021219
Fri 553159 1766482 1406979 1922542 1173163 2516285 1316412
Sat 956702 926344 1464396 2045854 1148131 2295788 1658585
위의 경우 개별 건수의 합보다는 해당 합의 비율이 우리에게 보다 도움이 되며, 일주일의 다른 요일들과의 비교를 위해, 비율은 전체 표가 아닌 각 열의 총계를 기준으로 만들려고 합니다. 따라서 prop.table 함수에 2를 두 번째 인수로 전달하여 열 합계를 기반으로 비율을 요청합니다. levelplot 함수를 사용하여 이 비율을 시각적으로 표시할 수도 있습니다.
levelplot(prop.table(rxs2, 2), cuts = 4, xlab = "", ylab = "", main = "Distribution of taxis by day of week")
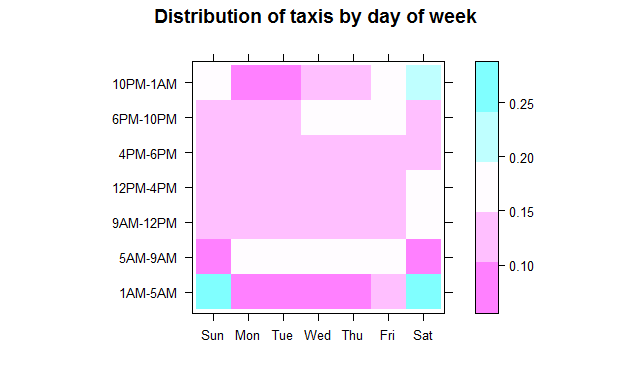
위의 plot에서 흥미로운 결과들이 나타납니다.
- 른 아침(오전 5시부터 오전 9시까지) 택시 사용은 주말에는 가장 낮으며, 월요일에는 조금 높아집니다(월요병 효과?).
- 업무 시간(오전 9시부터 오후 6시사이) 동안, 주말을 포함하여 주중 매일 같은 비율의 택시 사용(약 42-45 %)이 발생합니다. 즉, 어떤 요일인지에 관계없이 모든 택시 사용의 절반 이하 가량이 오전 9시부터 오후 6시까지 발생합니다.
- 목요일과 금요일 저녁에는 오후 6시부터 오후 10시까지 택시 사용이 증가함을 볼 수 있으며, 금요일 오후 10시부터 오전 1시까지 특히 토요일 저녁에 사용이 급증합니다. 오전 1시부터 오전 5시까지 택시 사용 증가 현상은 토요일(금요일 밤 늦게까지)에 일어나고 일요일(토요일 심야 운행)에는 더욱 그렇습니다. 다른 날에는 해당 시간대의 운행율이 급속도로 낮아지지만, 금요일에는 약간 개선됩니다 (예상대로!). 즉, 목요일에 많은 사람들이 나가지만 늦게까지는 머무르지 않고, 훨씬 더 많은 사람들이 금요일 저녁에 나가서 늦게까지 머무르는 것입니다. 그러나 토요일이 대부분의 사람들이 정말로 늦은 나들이를 하기 위해 선택한 날임을 알 수 있습니다.