일단 데이터가 분석을 위해서 읽어들여지면, 우리는 분석에 착수하는 데 필요한 흥미롭거나 연관 있어 보이는 특성(feature)들에 대해 생각하는 것을 시작할 수 있습니다. 우리의 목표는 주로 탐색(exploratory)입니다. 우리는 데이터를 기반으로 한 이야기를 하고 싶은 것입니다. 이러한 의미에서, 데이터에 포함된 어떠한 정보라도 유용할 수 있습니다. 더하여, 기존 데이터 요소에서 새로운 정보 (또는 특성)를 추출할 수 있습니다. 어떤 특성을 추출할 지에 대하여 고려하는 것 뿐만 아니라, 해당 열의 데이터 유형이 무엇인지도 잘 생각해야 이후에 분석을 적절하게 실행할 수 있습니다. 첫 번째 예로서, 팁을 지불한 승객의 비율을 추출하기 위한 간단한 변환을 살펴 보겠습니다.
여기서 우리는 앞으로 여러 번 다시 사용하게 될 rxDataStep 함수를 처음 만나게 됩니다. rxDataStep은 변환 작업에서는 필수적인 함수이며, (rxMerge, rxSort와 함께) RevoScaleR에서 가장 중요한 데이터 변환 함수 입니다. 그 밖의 다른 대부분의 분석 함수들은 데이터의 요약 및 모델링 함수들 입니다. rxDataStep을 사용하여 다음을 수행할 수 있습니다.
- 기존 열 수정 또는 데이터에 새 열 추가
- 새 파일에 쓰기 전에 데이터에서 특정 열 유지 또는 삭제
- 새 파일에 쓰기 전에 데이터의 특정 행 유지 또는 삭제
로컬 컴퓨팅 컨텍스트에서 rxDataStep을 실행할 때에는 data.frame 또는 CSV 또는 XDF 파일을 지정할 수 있는 inData 인수를 지정합니다.(나중에 계산 컨텍스트를 SQL Server 또는 HDFS로 변경하여 원격 분산 컴퓨팅 컨텍스트에서의 데이터 변환을 실행할 수 있습니다.) 또한 출력 할 파일을 지정하는 outFile 인수는, inData와 outFile이 모두 동일한 파일을 지정하는 경우에는 반드시 overwrite = TRUE로 설정하여야 합니다. ** outFile은 선택적 인수입니다.이 인수를 생략하면 결과가 data.frame 형식으로 출력됩니다. 그러나 대부분의 경우 이는 우리가 원하는 것이 아니므로 outFile을 지정할 필요가 있습니다. **
팁이 지불된 비율을 계산하기 위한 간단한 변환부터 시작해 보겠습니다.
rxDataStep(nyc_xdf, nyc_xdf,
transforms = list(tip_percent = ifelse(fare_amount > 0 & tip_amount < fare_amount, round(tip_amount*100 / fare_amount, 0), NA)),
overwrite = TRUE)
rxSummary( ~ tip_percent, nyc_xdf)
Rows Processed: 69406520
Call:
rxSummary(formula = ~tip_percent, data = nyc_xdf)
Summary Statistics Results for: ~tip_percent
Data: nyc_xdf (RxXdfData Data Source)
File name: yellow_tripdata_2016.xdf
Number of valid observations: 70710614
Name Mean StdDev Min Max ValidObs MissingObs
tip_percent 13.97823 11.87074 -1 100 70596806 113808
위에서 요약을 얻는 것과는 약간 다른 방법이 있습니다. 앞서의 rxDataStep 문 대신에 rxSummary에서 직접 변환을 수행할 수 있습니다. 이 두 번째 방법에서는, 변환은 데이터를 별도로 생성하여 기록하지 않은 상태에서 rxSummary에 의해 실행 중에 수행됩니다. IO 오버 헤드가 낮기 때문데, 이 두 번째 방법은 단일 실행에서 보다 효율적입니다. RevoScaleR의 모든 요약 함수 및 분석 함수에서 다음과 같이 새로운 열을 실행 중에 만들어 낼 수 있습니다.이는 변환이 데이터의 기존 열에서 파생된 직접적인 변환인 경우 특히 유용합니다. 다음 예제에서는 rxCrossTabs 내에서 변환을 실행하여, (현재 문자열로 저장 되어 있는)tpep_pickup_datetime에서 데이터의 월 및 연도를 가져옵니다. 그런 다음 rxCrossTabs를 통하여 각 연도와 월의 조합(combination)된 수를 제공할 수 있도록, 월 및 데이터를 factor 열로 변환합니다.
이는 변환이 데이터의 기존 열에서 파생된 직접적인 변환인 경우 특히 유용합니다. 다음 예제에서는 rxCrossTabs 내에서 변환을 실행하여, (현재 문자열로 저장 되어 있는)tpep_pickup_datetime에서 데이터의 월 및 연도를 가져옵니다. 그런 다음 rxCrossTabs를 통하여 각 연도와 월의 조합(combination)된 수를 제공할 수 있도록, 월 및 데이터를 factor 열로 변환합니다.
전체 데이터 읽기
이제 MRS를 사용하여 전체 데이터를 로드 합니다. MRS는 플랫 파일을 다음 두 가지 방식으로 처리합니다.
- 플랫 파일로 직접 작업 할 수 있습니다. 즉, 플랫 파일로 직접 읽고 쓸 수 있으며,
- 플랫 파일을 XDF(XDF는 외부 데이터 프레임-external data frame-을 나타냄) 형식으로 변환할 수 있습니다.
두 번 째 방법을 선택하여 사용하며, 선택한 이유에 대해서는 다음 섹션에서 설명합니다. 플랫 파일을 XDF로 변환하기 위하여 rxImport 함수를 사용합니다. append = "rows"를 사용하면, 여러 개의 플랫 파일을 단일 XDF 파일로 결합할 수 있습니다.
input_xdf <- 'yellow_tripdata_2016.xdf'
library(lubridate)
most_recent_date <- ymd("2016-07-01") # 일자 정보는 의미가 없음
st <- Sys.time()
for(ii in 1:6) { # 각각의 월 데이터를 가져와서 첫 달 데이터에 추가
file_date <- most_recent_date - months(ii)
input_csv <- sprintf('yellow_tripsample_%s.csv', substr(file_date, 1, 7))
append <- if (ii == 1) "none" else "rows"
rxImport(input_csv, input_xdf, colClasses = col_classes, overwrite = TRUE, append = append)
print(input_csv)
}
Sys.time() - st # stores the time it took to import
Rows Processed: 10906858
[1] "yellow_tripdata_2016-01.csv"
Rows Processed: 11382049
[1] "yellow_tripdata_2016-02.csv"
Rows Processed: 12210952
[1] "yellow_tripdata_2016-03.csv"
Rows Processed: 11934338
[1] "yellow_tripdata_2016-04.csv"
Rows Processed: 11836853
[1] "yellow_tripdata_2016-05.csv"
Rows Processed: 11135470
[1] "yellow_tripdata_2016-06.csv"
Time difference of 13.96592 mins
지역 찾기(Finding neighborhoods)
마지막 부분에서 우리는 Manhattan에 대한 shapefile을 mht_shapefile이라는 객체에 저장했습니다. 이 객체는 Manhattan 지역의 지도를 그리는 데 사용되었습니다. 이제 우리는 동일한 shapefile을 over 함수(sp 패키지의 일부)와 함께 사용하여 각각의 운행에 대하여 승차 및 하차 지역을 찾는 방법을 살펴 보겠습니다. 이전에 만들어 두었던 NYC 택시 데이터의 샘플을 사용하여 data.frame을 사용하여 이를 수행 할 수있는 방법을 보여주고, 코드를 변환 함수로 감싸고(wrap), 이를 XDF 데이터에 적용하기 위한 연습으로 남겨 둘 것입니다.
승차 지역 컬럼을 nyc_sample_df에 추가하려면 다음의 작업을 수행해야 합니다. pickup_latitude 및 pickup_longitude의 NA 값들을 0으로 바꿔야 하며, 바꾸지 않을 경우 오류가 발생합니다. coordinates 함수를 사용하여 위의 두 열이 데이터의 지리적 좌표를 나타내도록 지정합니다. over 함수를 사용하여 위에 지정된 좌표를 기반으로 한 지역 정보를 얻어서 지역 정보가 포함된 data.frame을 반환하게 합니다. 관련된 열 이름을 얻어낸 후, cbind를 사용하여 결과를 원래 데이터에 연결 시킵니다.
# 좌표 컬럼을 가져와서, NA를 0으로 치환함
data_coords <- transmute(nyc_sample_df,
long = ifelse(is.na(pickup_longitude), 0, pickup_longitude),
lat = ifelse(is.na(pickup_latitude), 0, pickup_latitude)
)
# 좌표에 해당하는 컬럼명을 지정함
coordinates(data_coords) <- c('long', 'lat')
# 좌표에 기반한 지역 정보를 반환
nhoods <- over(data_coords, mht_shapefile)
# nhoods의 열이름 바꿈
names(nhoods) <- paste('pickup', tolower(names(nhoods)), sep = '_')
# 원래 데이터에 지역정보를 추가함
nyc_sample_df <- cbind(nyc_sample_df, nhoods[, grep('name|city', names(nhoods))])
head(nyc_sample_df)
VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count
1 2 2016-01-01 00:00:00 2016-01-01 00:00:00 2
2 2 2016-01-01 00:00:00 2016-01-01 00:00:00 5
3 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1
4 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1
5 2 2016-01-01 00:00:00 2016-01-01 00:00:00 3
6 2 2016-01-01 00:00:00 2016-01-01 00:18:30 2
trip_distance pickup_longitude pickup_latitude RatecodeID store_and_fwd_flag
1 1.10 -73.99037 40.73470 1 N
2 4.90 -73.98078 40.72991 1 N
3 10.54 -73.98455 40.67957 1 N
4 4.75 -73.99347 40.71899 1 N
5 1.76 -73.96062 40.78133 1 N
6 5.52 -73.98012 40.74305 1 N
dropoff_longitude dropoff_latitude payment_type fare_amount extra mta_tax
1 -73.98184 40.73241 2 7.5 0.5 0.5
2 -73.94447 40.71668 1 18.0 0.5 0.5
3 -73.95027 40.78893 1 33.0 0.5 0.5
4 -73.96224 40.65733 2 16.5 0.0 0.5
5 -73.97726 40.75851 2 8.0 0.0 0.5
6 -73.91349 40.76314 2 19.0 0.5 0.5
tip_amount tolls_amount improvement_surcharge total_amount
1 0 0 0.3 8.8
2 0 0 0.3 19.3
3 0 0 0.3 34.3
4 0 0 0.3 17.3
5 0 0 0.3 8.8
6 0 0 0.3 20.3
pickup_city pickup_name
1 New York City-Manhattan Greenwich Village
2 New York City-Manhattan East Village
3 <NA> <NA>
4 New York City-Manhattan Lower East Side
5 New York City-Manhattan Upper East Side
6 New York City-Manhattan Gramercy
전체 데이터에 대하여 위의 변환을 실행하려면, 위 코드를 transfromFunc 인수를 통해 rxDataStep에 전달할 수 있도록 변환 함수로 래핑해야 합니다. 우리는 변환 함수 find_nhoods를 호출하는 것입니다. 우리가 작성한 변환 함수는 탑승 지역과 구역 그리고 하차 지역과 구역을 모두 추가합니다.
find_nhoods <- function(data) {
# 승차 위도와 경도를 추출하고, 해당 지역 정보를 조회함
pickup_longitude <- ifelse(is.na(data$pickup_longitude), 0, data$pickup_longitude)
pickup_latitude <- ifelse(is.na(data$pickup_latitude), 0, data$pickup_latitude)
data_coords <- data.frame(long = pickup_longitude, lat = pickup_latitude)
coordinates(data_coords) <- c('long', 'lat')
nhoods <- over(data_coords, shapefile)
## 데이터에 승차 지역 및 도시 컬럼 추가
data$pickup_nhood <- nhoods$NAME
data$pickup_borough <- nhoods$CITY
# 하차 위도와 경도를 추출하고, 해당 지역 정보를 조회함
dropoff_longitude <- ifelse(is.na(data$dropoff_longitude), 0, data$dropoff_longitude)
dropoff_latitude <- ifelse(is.na(data$dropoff_latitude), 0, data$dropoff_latitude)
data_coords <- data.frame(long = dropoff_longitude, lat = dropoff_latitude)
coordinates(data_coords) <- c('long', 'lat')
nhoods <- over(data_coords, shapefile)
## 데이터에 하차 지역 및 도시 컬럼 추가
data$dropoff_nhood <- nhoods$NAME
data$dropoff_borough <- nhoods$CITY
## 새 컬럼이 추가된 데이터 반환
data
}
이제 우리는 함수를 만들었으므로, 테스트를 진행할 차례입니다. 샘플 데이터 nyc_sample_df에서 rxDataStep을 실행하여 테스트를 수행합니다. 이러한 방식은, 큰 XDF 파일 nyc_xdf에서 변환을 실행하기에 앞서 변환이 제대로 작동하는지 확인하는 데 있어서 매우 좋은 방법입니다. data.frame에 변환을 적용하면서 얻는 오류 메시지는, 때로는 XDF에서 보다 더 많은 정보를 제공하기 때문에, 오류를 추적하고 디버깅하는 것이 더 쉽습니다. 이제 rxDataStep을 사용하여 nyc_sample_df(outFile 인수 없음)를 대상으로 변환 함수 find_nhoods를 적용한 이후 데이터가 어떻게 보이는지를 살펴봅시다.
# rxDataStep을 사용하여 data.frame에 변환 함수 테스트
head(rxDataStep(nyc_sample_df, transformFunc = find_nhoods, transformPackages = c("sp", "maptools"),
transformObjects = list(shapefile = mht_shapefile)))
VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count trip_distance
1 2 2016-01-01 00:00:00 2016-01-01 00:00:00 2 1.10
2 2 2016-01-01 00:00:00 2016-01-01 00:00:00 5 4.90
3 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 10.54
4 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 4.75
5 2 2016-01-01 00:00:00 2016-01-01 00:00:00 3 1.76
6 2 2016-01-01 00:00:00 2016-01-01 00:18:30 2 5.52
pickup_longitude pickup_latitude RatecodeID store_and_fwd_flag dropoff_longitude
1 -73.99037 40.73470 1 N -73.98184
2 -73.98078 40.72991 1 N -73.94447
3 -73.98455 40.67957 1 N -73.95027
4 -73.99347 40.71899 1 N -73.96224
5 -73.96062 40.78133 1 N -73.97726
6 -73.98012 40.74305 1 N -73.91349
dropoff_latitude payment_type fare_amount extra mta_tax tip_amount tolls_amount
1 40.73241 2 7.5 0.5 0.5 0 0
2 40.71668 1 18.0 0.5 0.5 0 0
3 40.78893 1 33.0 0.5 0.5 0 0
4 40.65733 2 16.5 0.0 0.5 0 0
5 40.75851 2 8.0 0.0 0.5 0 0
6 40.76314 2 19.0 0.5 0.5 0 0
improvement_surcharge total_amount pickup_nhood pickup_borough
1 0.3 8.8 Greenwich Village New York City-Manhattan
2 0.3 19.3 East Village New York City-Manhattan
3 0.3 34.3 Boerum Hill New York City-Brooklyn
4 0.3 17.3 Lower East Side New York City-Manhattan
5 0.3 8.8 Upper East Side New York City-Manhattan
6 0.3 20.3 Gramercy New York City-Manhattan
dropoff_nhood dropoff_borough
1 Gramercy New York City-Manhattan
2 <NA> <NA>
3 Yorkville New York City-Manhattan
4 <NA> <NA>
5 Midtown New York City-Manhattan
6 Astoria-Long Island City New York City-Queens
데이터의 마지막 4개 열은 우리가 원하는 지역 정보 열에 해당합니다. 따라서 우리는 nyc_xdf에서 실행을 해도, 변환이 잘 작동할 것임을 확신할 수 있습니다.
st <- Sys.time()
rxDataStep(nyc_xdf, nyc_xdf, overwrite = TRUE, transformFunc = find_nhoods, transformPackages = c("sp", "maptools", "rgeos"),
transformObjects = list(shapefile = mht_shapefile))
Sys.time() - st
rxGetInfo(nyc_xdf, numRows = 5)
Time difference of 30.77251 mins
File name: C:\Data\NYC_taxi\yellow_tripdata_2016.xdf
Number of observations: 69406520
Number of variables: 29
Number of blocks: 141
Compression type: zlib
Data (5 rows starting with row 1):
VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count trip_distance
1 2 2016-01-01 00:00:00 2016-01-01 00:00:00 2 1.10
2 2 2016-01-01 00:00:00 2016-01-01 00:00:00 5 4.90
3 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 10.54
4 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 4.75
5 2 2016-01-01 00:00:00 2016-01-01 00:00:00 3 1.76
pickup_longitude pickup_latitude RatecodeID store_and_fwd_flag dropoff_longitude
1 -73.99037 40.73470 1 N -73.98184
2 -73.98078 40.72991 1 N -73.94447
3 -73.98455 40.67957 1 N -73.95027
4 -73.99347 40.71899 1 N -73.96224
5 -73.96062 40.78133 1 N -73.97726
dropoff_latitude payment_type fare_amount extra mta_tax tip_amount tolls_amount
1 40.73241 2 7.5 0.5 0.5 0 0
2 40.71668 1 18.0 0.5 0.5 0 0
3 40.78893 1 33.0 0.5 0.5 0 0
4 40.65733 2 16.5 0.0 0.5 0 0
5 40.75851 2 8.0 0.0 0.5 0 0
improvement_surcharge total_amount tip_percent pickup_hour pickup_dow
1 0.3 8.8 0 10PM-1AM Fri
2 0.3 19.3 0 10PM-1AM Fri
3 0.3 34.3 0 10PM-1AM Fri
4 0.3 17.3 0 10PM-1AM Fri
5 0.3 8.8 0 10PM-1AM Fri
dropoff_hour dropoff_dow trip_duration pickup_nhood pickup_borough
1 10PM-1AM Fri 0 Greenwich Village New York City-Manhattan
2 10PM-1AM Fri 0 East Village New York City-Manhattan
3 10PM-1AM Fri 0 Boerum Hill New York City-Brooklyn
4 10PM-1AM Fri 0 Lower East Side New York City-Manhattan
5 10PM-1AM Fri 0 Upper East Side New York City-Manhattan
dropoff_nhood dropoff_borough
1 Gramercy New York City-Manhattan
2 <NA> <NA>
3 Yorkville New York City-Manhattan
4 <NA> <NA>
5 Midtown New York City-Manhattan
데이터 읽기
보통 우리가 대답하려고 하는 질문으로부터 분석은 시작되며, 이는 우리의 답변에 도움을 줄 수 있는 데이터의 수집으로 이어집니다. 또한 데이터를 수집한 시점에, 특정한 질문에 대한 답변을 위한 작업을 바로 시작하는 것 대신에, 데이터를 수집하는 시점에서 명확하지 않은 추세를 찾아 데이터를 탐색하기도 합니다. 이는 때때로 탐색적 데이터 분석(exploratory data analysis)이라고 불리워지며, 데이터가 어떤 종류의 질문에 대답할 수 있는지를 판단하는 데 큰 도움이 될 수 있습니다.
학습 목표
이 섹션을 통하여 우리는 다음 내용을 배우게 됩니다.
- RevoScaleR 기능이 메모리(data.frame)의 데이터 및 디스크의 데이터와 함께 작동하는 방식
- 디스크의 데이터는 플랫 파일(예 : CSV 파일)과 MRS 고유의 XDF 형식으로 구성될 수 있으며 로컬 또는 HDFS와 같은 분산 파일 시스템에 저장 가능
- rxImport를 사용하여 플랫 파일로 부터 XDF 파일을 만드는 방법
- 플랫 파일에서 XDF 로의 변환 선택을 위한 고려 사항(장점과 단점)
지역별 표시(Plotting neighborhoods)
이제 데이터에 탑승 및 하차 지역이라는 또 다른 특성(feature) 집합을 추가합니다. 경도와 위도로부터 지역 정보를 얻는 것은 우리가 쉽게 하드 코딩 할 수 있는 것이 아니기 때문에, 몇 개의 GIS 패키지와 shapefile(courtesy of Zillow)을 사용합니다. shapefile은 지리적 영역을 구분하는 경계에 대한 정보를 포함한 지리 정보가 들어있는 파일입니다. ZillowNeighborhoods-NY.shpfile에는 NYC 지역에 대한 정보가 있습니다.
우리는 맨해튼 지역의 지도에 플롯을 그리는 것으로 시작하며, 지역 경계를 확인하고 지역의 이름에 익숙해 지도록 합니다. 아래 플롯이 어떻게 생성되었는지에 대한 자세한 내용은 이 강의의 내용을 넘어서기 때문에, 보다 자세한 내용은 maptools 라이브러리에 대한 설명서를 확인하는 것을 권고 드립니다.
library(rgeos)
library(maptools)
nyc_shapefile <- readShapePoly('ZillowNeighborhoods-NY/ZillowNeighborhoods-NY.shp')
mht_shapefile <- subset(nyc_shapefile, str_detect(CITY, 'New York City-Manhattan'))
mht_shapefile@data$id <- as.character(mht_shapefile@data$NAME)
mht.points <- fortify(gBuffer(mht_shapefile, byid = TRUE, width = 0), region = "NAME")
mht.df <- inner_join(mht.points, mht_shapefile@data, by = "id")
library(dplyr)
mht.cent <- mht.df %>%
group_by(id) %>%
summarize(long = median(long), lat = median(lat))
library(ggrepel)
ggplot(mht.df, aes(long, lat, fill = id)) +
geom_polygon() +
geom_path(color = "white") +
coord_equal() +
theme(legend.position = "none") +
geom_text_repel(aes(label = id), data = mht.cent, size = 3)
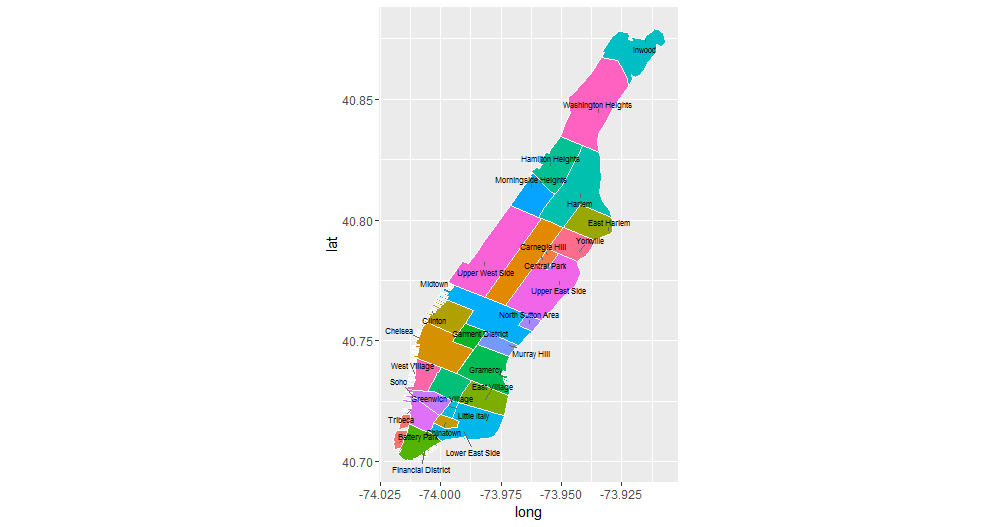
새로운 열 조사
변환이 어느 정도 효과가 있었는지를 확인하기 위해, 만들어진 새로운 열을 살펴 보겠습니다. 우리는 rxSummary 함수를 사용하여 데이터의 통계적 요약을 얻습니다. rxSummary 함수는 기본 R에있는 Summary 함수와 비슷하며 두 가지 방법으로 작동됩니다 (Summary 함수는 data.frame에서만 작동)
- 숫자 열에 대한 수치 요약을 제공합니다 (백분위 수 제외, 여기에는 rxQuantile 함수를 사용함).
- factor 열의 각 수준에 대해 합계값을 제공합니다.
우리는 다른 많은 R 모델링 또는 플로팅 함수에서 사용하는 것과 동일한 수식 표기법을 사용하여 요약할 열을 지정합니다. 예를 들어 아래에서는 pickup_hour 및 pickup_dow (둘 모두 factor)와 trip_duration (숫자, 초 단위)의 요약을 보려고 합니다.
rxs1 <- rxSummary( ~ pickup_hour + pickup_dow + trip_duration, nyc_xdf)
# 합계 숫자 옆에 비율에 대한 열을 추가 할 수 있습니다.
rxs1$categorical <- lapply(rxs1$categorical, function(x) cbind(x, prop = round(prop.table(x$Counts), 2)))
rxs1
Call:
rxSummary(formula = ~pickup_hour + pickup_dow + trip_duration,
data = nyc_xdf)
Summary Statistics Results for: ~pickup_hour + pickup_dow + trip_duration
Data: nyc_xdf (RxXdfData Data Source)
File name: yellow_tripdata_2016.xdf
Number of valid observations: 69406520
Name Mean StdDev Min Max ValidObs MissingObs
trip_duration 933.9168 119243.5 -631148790 11538803 69406520 0
Category Counts for pickup_hour
Number of categories: 7
Number of valid observations: 69406520
Number of missing observations: 0
pickup_hour Counts prop
1AM-5AM 3801430 0.05
5AM-9AM 10630653 0.15
9AM-12PM 9765429 0.14
12PM-4PM 13473045 0.19
4PM-6PM 7946899 0.11
6PM-10PM 16138968 0.23
10PM-1AM 7650096 0.11
Category Counts for pickup_dow
Number of categories: 7
Number of valid observations: 69406520
Number of missing observations: 0
pickup_dow Counts prop
Sun 9267881 0.13
Mon 8938785 0.13
Tue 9667525 0.14
Wed 9982769 0.14
Thu 10398738 0.15
Fri 10655022 0.15
Sat 10495800 0.15
플러스 기호 (pickup_dow + pickup_hour) 대신 콜론 (pickup_dow : pickup_hour)으로 두 변수를 구분하면 개별 컬럼 대신 두 개의 인수 facor 열의 수준(level) 별로 각 조합에 대한 요약을 얻을 수 있습니다.
rxs2 <- rxSummary( ~ pickup_dow:pickup_hour, nyc_xdf)
rxs2 <- tidyr::spread(rxs2$categorical[[1]], key = 'pickup_hour', value = 'Counts')
row.names(rxs2) <- rxs2[ , 1]
rxs2 <- as.matrix(rxs2[ , -1])
rxs2
1AM-5AM 5AM-9AM 9AM-12PM 12PM-4PM 4PM-6PM 6PM-10PM 10PM-1AM
Sun 1040233 740157 1396409 1980752 1032434 1697529 1380367
Mon 304474 1630951 1268326 1838143 1133728 2096219 666944
Tue 278407 1840134 1382381 1882356 1151837 2390506 741904
Wed 313809 1854757 1417953 1880896 1142071 2508618 864665
Thu 354646 1871828 1428985 1922502 1165535 2634023 1021219
Fri 553159 1766482 1406979 1922542 1173163 2516285 1316412
Sat 956702 926344 1464396 2045854 1148131 2295788 1658585
위의 경우 개별 건수의 합보다는 해당 합의 비율이 우리에게 보다 도움이 되며, 일주일의 다른 요일들과의 비교를 위해, 비율은 전체 표가 아닌 각 열의 총계를 기준으로 만들려고 합니다. 따라서 prop.table 함수에 2를 두 번째 인수로 전달하여 열 합계를 기반으로 비율을 요청합니다. levelplot 함수를 사용하여 이 비율을 시각적으로 표시할 수도 있습니다.
levelplot(prop.table(rxs2, 2), cuts = 4, xlab = "", ylab = "", main = "Distribution of taxis by day of week")
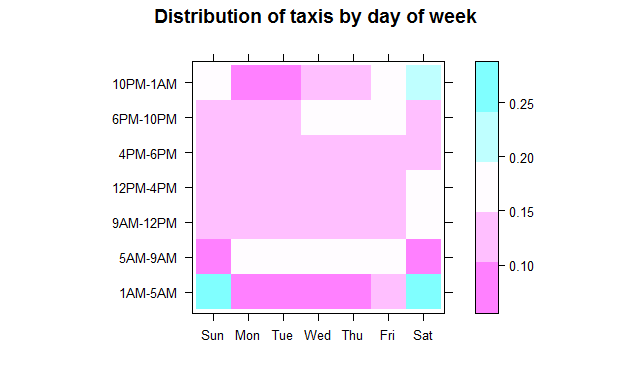
위의 plot에서 흥미로운 결과들이 나타납니다.
- 른 아침(오전 5시부터 오전 9시까지) 택시 사용은 주말에는 가장 낮으며, 월요일에는 조금 높아집니다(월요병 효과?).
- 업무 시간(오전 9시부터 오후 6시사이) 동안, 주말을 포함하여 주중 매일 같은 비율의 택시 사용(약 42-45 %)이 발생합니다. 즉, 어떤 요일인지에 관계없이 모든 택시 사용의 절반 이하 가량이 오전 9시부터 오후 6시까지 발생합니다.
- 목요일과 금요일 저녁에는 오후 6시부터 오후 10시까지 택시 사용이 증가함을 볼 수 있으며, 금요일 오후 10시부터 오전 1시까지 특히 토요일 저녁에 사용이 급증합니다. 오전 1시부터 오전 5시까지 택시 사용 증가 현상은 토요일(금요일 밤 늦게까지)에 일어나고 일요일(토요일 심야 운행)에는 더욱 그렇습니다. 다른 날에는 해당 시간대의 운행율이 급속도로 낮아지지만, 금요일에는 약간 개선됩니다 (예상대로!). 즉, 목요일에 많은 사람들이 나가지만 늦게까지는 머무르지 않고, 훨씬 더 많은 사람들이 금요일 저녁에 나가서 늦게까지 머무르는 것입니다. 그러나 토요일이 대부분의 사람들이 정말로 늦은 나들이를 하기 위해 선택한 날임을 알 수 있습니다.
이전 파트의 마지막 부분에서 간단한 한 줄 변환을 수행하기 위해 rxDataStep이 소개 되었습니다. 이제 다시 rxDataStep을 사용하여 다른 변환을 수행하여 봅시다. 이번에는 보다 복잡한 변환을 수행합니다. 위의 예제에서와 같이, 때로는 transforms 인수를 사용하여 좀 더 복잡한 변환을 더 길게 작성된 단일 행으로써 수행할 수도 있습니다. 그러나 보다 더 깔끔한 방법은 변환 로직을 포함하는 함수를 만들어 transformFunc 인수에 전달하는 것입니다. 이 함수는 특정 데이터를 입력으로 사용하고 일반적으로 하나 이상의 열이 추가되거나 수정된 출력과 동일한 데이터를 반환합니다. 보다 구체적으로 말하자면, 변환 함수에 대한 입력은 요소가 열인 목록(list)이 됩니다. 이를 제외한 나머지 부분은 통상적인 R의 함수와 동일합니다. transformFunc 인수를 사용하면 변환 함수의 작성에만 집중할 수 있기 때문에, 전체 데이터에서 실행하기 전에 샘플 data.frame에서 신속하게 기능을 테스트 할 수 있습니다.
뉴욕 택시 데이터에서, 우리는 요일 및 시간대를 기준으로 한 운행 내역들을 비교하고 싶습니다. 이 두 열은 아직 존재하지 않지만, 탑승 날짜와 시간 및 하차 날짜와 시간에서 추출할 수 있습니다. 위의 특성(feature)들을 추출하기 위해, 우리는 날짜 및 시간 열을 처리하는 데 유용한 함수가 포함되어 있는 lubridate 패키지를 사용합니다. 변환을 수행하기 위해 xforms라는 변환 함수를 사용합니다.
xforms <- function(data) { # 날짜 및 시간 특성 추출을 위한 변환 함수
weekday_labels <- c('Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat')
cut_levels <- c(1, 5, 9, 12, 16, 18, 22)
hour_labels <- c('1AM-5AM', '5AM-9AM', '9AM-12PM', '12PM-4PM', '4PM-6PM', '6PM-10PM', '10PM-1AM')
pickup_datetime <- ymd_hms(data$tpep_pickup_datetime, tz = "UTC")
pickup_hour <- addNA(cut(hour(pickup_datetime), cut_levels))
pickup_dow <- factor(wday(pickup_datetime), levels = 1:7, labels = weekday_labels)
levels(pickup_hour) <- hour_labels
dropoff_datetime <- ymd_hms(data$tpep_dropoff_datetime, tz = "UTC")
dropoff_hour <- addNA(cut(hour(dropoff_datetime), cut_levels))
dropoff_dow <- factor(wday(dropoff_datetime), levels = 1:7, labels = weekday_labels)
levels(dropoff_hour) <- hour_labels
data$pickup_hour <- pickup_hour
data$pickup_dow <- pickup_dow
data$dropoff_hour <- dropoff_hour
data$dropoff_dow <- dropoff_dow
data$trip_duration <- as.integer(as.duration(dropoff_datetime - pickup_datetime))
data
}
변환을 데이터에 적용하기 전에 데이터를 테스트 하고 변환이 올바르게 작동하는지를 확인하는 것이 좋습니다. 우리는 이러한 목적으로 데이터의 샘플을 따로 때어내어, data.frame으로 저장합니다. nyc_sample_df에 변환 함수를 실행하면, 원래 데이터에 새로운 열이 추가된 데이터가 반환됩니다.
library(lubridate)
Sys.setenv(TZ = "US/Eastern") # 이 데이터셋에는 중요하지 않음
head(xforms(nyc_sample_df)) # data.frame에 대하여 변환을 테스트
VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count trip_distance
1 2 2016-01-01 00:00:00 2016-01-01 00:00:00 2 1.10
2 2 2016-01-01 00:00:00 2016-01-01 00:00:00 5 4.90
3 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 10.54
4 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 4.75
5 2 2016-01-01 00:00:00 2016-01-01 00:00:00 3 1.76
6 2 2016-01-01 00:00:00 2016-01-01 00:18:30 2 5.52
pickup_longitude pickup_latitude RatecodeID store_and_fwd_flag dropoff_longitude
1 -73.99037 40.73470 1 N -73.98184
2 -73.98078 40.72991 1 N -73.94447
3 -73.98455 40.67957 1 N -73.95027
4 -73.99347 40.71899 1 N -73.96224
5 -73.96062 40.78133 1 N -73.97726
6 -73.98012 40.74305 1 N -73.91349
dropoff_latitude payment_type fare_amount extra mta_tax tip_amount tolls_amount
1 40.73241 2 7.5 0.5 0.5 0 0
2 40.71668 1 18.0 0.5 0.5 0 0
3 40.78893 1 33.0 0.5 0.5 0 0
4 40.65733 2 16.5 0.0 0.5 0 0
5 40.75851 2 8.0 0.0 0.5 0 0
6 40.76314 2 19.0 0.5 0.5 0 0
improvement_surcharge total_amount pickup_hour pickup_dow dropoff_hour
1 0.3 8.8 10PM-1AM Fri 10PM-1AM
2 0.3 19.3 10PM-1AM Fri 10PM-1AM
3 0.3 34.3 10PM-1AM Fri 10PM-1AM
4 0.3 17.3 10PM-1AM Fri 10PM-1AM
5 0.3 8.8 10PM-1AM Fri 10PM-1AM
6 0.3 20.3 10PM-1AM Fri 10PM-1AM
dropoff_dow trip_duration
1 Fri 0
2 Fri 0
3 Fri 0
4 Fri 0
5 Fri 0
6 Fri 1110
변환을 적용하기 전에 마지막 테스트를 하나 실행합니다. rxDataStep은 data.frame 입력에서도 작동하며, outFile 인수를 지정하지 않고 남겨두면 data.frame을 반환한다는 것이 기억나시나요? 따라서 transform 함수를 transformFunc에 전달하고 transformPackages에 수행에 필요한 패키지를 지정하는 방식으로 rxDataStep을 사용하여 위의 테스트를 수행 할 수 있습니다.
head(rxDataStep(nyc_sample_df, transformFunc = xforms, transformPackages = "lubridate"))
Rows Processed: 1000
VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count trip_distance
1 2 2016-01-01 00:00:00 2016-01-01 00:00:00 2 1.10
2 2 2016-01-01 00:00:00 2016-01-01 00:00:00 5 4.90
3 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 10.54
4 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 4.75
5 2 2016-01-01 00:00:00 2016-01-01 00:00:00 3 1.76
6 2 2016-01-01 00:00:00 2016-01-01 00:18:30 2 5.52
pickup_longitude pickup_latitude RatecodeID store_and_fwd_flag dropoff_longitude
1 -73.99037 40.73470 1 N -73.98184
2 -73.98078 40.72991 1 N -73.94447
3 -73.98455 40.67957 1 N -73.95027
4 -73.99347 40.71899 1 N -73.96224
5 -73.96062 40.78133 1 N -73.97726
6 -73.98012 40.74305 1 N -73.91349
dropoff_latitude payment_type fare_amount extra mta_tax tip_amount tolls_amount
1 40.73241 2 7.5 0.5 0.5 0 0
2 40.71668 1 18.0 0.5 0.5 0 0
3 40.78893 1 33.0 0.5 0.5 0 0
4 40.65733 2 16.5 0.0 0.5 0 0
5 40.75851 2 8.0 0.0 0.5 0 0
6 40.76314 2 19.0 0.5 0.5 0 0
improvement_surcharge total_amount pickup_hour pickup_dow dropoff_hour
1 0.3 8.8 10PM-1AM Fri 10PM-1AM
2 0.3 19.3 10PM-1AM Fri 10PM-1AM
3 0.3 34.3 10PM-1AM Fri 10PM-1AM
4 0.3 17.3 10PM-1AM Fri 10PM-1AM
5 0.3 8.8 10PM-1AM Fri 10PM-1AM
6 0.3 20.3 10PM-1AM Fri 10PM-1AM
dropoff_dow trip_duration
1 Fri 0
2 Fri 0
3 Fri 0
4 Fri 0
5 Fri 0
6 Fri 1110
모든 것이 잘 작동하는 것 같습니다. 전체 데이터 집합에 대해 변환 함수를 실행해도 데이터가 성공적으로 실행된다는 것을 100% 보장하는 것은 아니지만, 무언가 잘못 작성한 것 때문에실패할 것으로 보이지는 않습니다. 만약 위의 경우에서 처럼 변환이 샘플 data.frame에서는 잘 실행되었는데 전체 데이터 세트에서는 실패하였는 때에는, 이는 보통 샘플 데이터에는 존재하지 않는 전체 데이터 셋에서의 무언가의 원인(예 : 누락 된 값)으로 인해 발생합니다. 이제 전체 데이터 셋에 대하여 변환을 실행합니다.
st <- Sys.time()
rxDataStep(nyc_xdf, nyc_xdf, overwrite = TRUE, transformFunc = xforms, transformPackages = "lubridate")
Sys.time() - st
Time difference of 11.07041 mins
열(column) 유형 검사
열 유형을 확인하고 이상한 점이 없는지 확인하는 것이 좋습니다. rxGetInfo 함수는 열의 유형은 물론, 숫자 열에 대한 낮은 값과 높은 값을 표시하여 주며, 이를 통하여 이상 값을 확인 또는 정상값 검사를 실행하는 데 유용합니다. numRows = 10 구문을 사용하여 데이터의 처음 10 개 행을 볼 수 있습니다.
rxGetInfo(nyc_xdf, getVarInfo = TRUE, numRows = 5) # 열 유형과 처음 10개 행 표시
File name: C:\Data\NYC_taxi\yellow_tripdata_2016.xdf
Number of observations: 69406520
Number of variables: 19
Number of blocks: 141
Compression type: zlib
Variable information:
Var 1: VendorID 2 factor levels: 2 1
Var 2: tpep_pickup_datetime, Type: character
Var 3: tpep_dropoff_datetime, Type: character
Var 4: passenger_count, Type: integer, Low/High: (0, 9)
Var 5: trip_distance, Type: numeric, Low/High: (-3390583.8000, 19072628.8000)
Var 6: pickup_longitude, Type: numeric, Low/High: (-165.0819, 118.4089)
Var 7: pickup_latitude, Type: numeric, Low/High: (-77.0395, 66.8568)
Var 8: RatecodeID, Type: integer, Low/High: (1, 99)
Var 9: store_and_fwd_flag 2 factor levels: N Y
Var 10: dropoff_longitude, Type: numeric, Low/High: (-161.6987, 106.2469)
Var 11: dropoff_latitude, Type: numeric, Low/High: (-77.0395, 405.3167)
Var 12: payment_type 5 factor levels: 2 1 3 4 5
Var 13: fare_amount, Type: numeric, Low/High: (-957.6000, 628544.7400)
Var 14: extra, Type: numeric, Low/High: (-58.5000, 648.8700)
Var 15: mta_tax, Type: numeric, Low/High: (-2.7000, 89.7000)
Var 16: tip_amount, Type: numeric, Low/High: (-220.8000, 998.1400)
Var 17: tolls_amount, Type: numeric, Low/High: (-99.9900, 1410.3200)
Var 18: improvement_surcharge, Type: numeric, Low/High: (-0.3000, 11.6400)
Var 19: total_amount, Type: numeric, Low/High: (-958.4000, 629033.7800)
Data (5 rows starting with row 1):
VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count trip_distance
1 2 2016-01-01 00:00:00 2016-01-01 00:00:00 2 1.10
2 2 2016-01-01 00:00:00 2016-01-01 00:00:00 5 4.90
3 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 10.54
4 2 2016-01-01 00:00:00 2016-01-01 00:00:00 1 4.75
5 2 2016-01-01 00:00:00 2016-01-01 00:00:00 3 1.76
pickup_longitude pickup_latitude RatecodeID store_and_fwd_flag dropoff_longitude
1 -73.99037 40.73470 1 N -73.98184
2 -73.98078 40.72991 1 N -73.94447
3 -73.98455 40.67957 1 N -73.95027
4 -73.99347 40.71899 1 N -73.96224
5 -73.96062 40.78133 1 N -73.97726
dropoff_latitude payment_type fare_amount extra mta_tax tip_amount tolls_amount
1 40.73241 2 7.5 0.5 0.5 0 0
2 40.71668 1 18.0 0.5 0.5 0 0
3 40.78893 1 33.0 0.5 0.5 0 0
4 40.65733 2 16.5 0.0 0.5 0 0
5 40.75851 2 8.0 0.0 0.5 0 0
improvement_surcharge total_amount
1 0.3 8.8
2 0.3 19.3
3 0.3 34.3
4 0.3 17.3
5 0.3 8.8
데이터 준비
원시 데이터는 분석에 직접 사용하기에는 적절하지 않은 경우가 많습니다. 원시 데이터를 로딩한 이후에, 데이터 과학자는 해당 데이터를 정제하고 현재 분석중인 데이터에 특성(feature) 항목들을 추가하는 데 많은 시간과 노력을 사용합니다. 데이터를 정리하는 방법은 한 편으로는 분석을 통하여 어떻게 상식적인 비즈니스를 이끌어 내고 특정 요구 조건을 만족 시킬수 있도록 하는지, 다른 한 편으로는 특정 분석 알고리즘에 대하여 데이터를 적용하기 위하여 해당 데이터를 어떻게 가공해야 하는 지에 따라 결정됩니다. 다시 말하면, 데이터 정제 업무는, 분석을 어렵게 만들지 않는 한도 내에서는, 다소간 주관적인 작업일 수 있습니다.
일반적인 데이터 준비 작업은 누락 값에 대한 처리 - 아웃 라이어 처리 - 데이터에 대한 세분화 수준 결정 (예 : 시간 변수가 초, 분 또는 시간 등일 경우) - 분석을 보다 재미 있고 쉽게 해석할 수 있도록 특성(feature)을 추가하거나 기존 특성을 기반으로 새로운 특성을 추출하는 것 등이 될 수 있습니다.
학습 목표
이 장을 읽은 후, 우리는 데이터에 대한 사전 검사를 수행하는 방법과, rxDataStep을 사용하여 기존 열을 수정하거나 새 열을 추가하거나, 더 복잡한 변환을 함수로 작성하여 감싼 후 rxDataStep에 직접 전달하거나, 작업한 내용의 재확인을 위하여 새로운 특성(feature) 정보를 조사하거나 요약하는 방법을 알게 될 것입니다.
XDF 와 CSV
XDF 파일은 압축되어 있기 때문에 CSV 파일보다 훨씬 크기가 작습니다. XDF 파일의 주요 장점은 CSV 파일보다 훨씬 빨리 파일을 읽고 처리 할 수 있다는 것입니다(얼마나 빨리 처리되는 지를 볼 수있는 간단한 벤치마크를 실행할 것입니다). XDF 파일 형식의 단점은 MRS만이 인식하고 사용할 수 있다는 것입니다. 따라서 우리가 XDF를 사용할 것인지 아니면 CSV를 사용할 것인지의 여부를 결정하려면 다음과 같은 관련된 I/O 장점과 단점을 이해해야 합니다.
- CSV에서 XDF로 변환하는 것은 그 자체로 런타임 시 비용이 됩니다.
- 일단 CSV가 XDF로 변환된 이후에는 XDF를 직접 처리하는 경우가 처리 시간(XDF 읽기 및 쓰기)이 빨라집니다.
EDA 워크 플로에서는 일반적으로 데이터는 정제 및 정리된 다음, 이를 다양한 모델링 및 데이터 마이닝 알고리즘에 제공됩니다. 그러므로 CSV에서 XDF로 변환하는 초기 런타임 소요 시간은 XDF 파일로 계속 작업하는 이후 단계의 런타임을 줄임으로써 빠르게 상쇄됩니다. 그러나 XDF 변환을 건너 뛰는 경우, 입력 준비가 완료된 데이터 세트에 대한 일회성 분석 모델링 알고리즘과 같은 종류의 작업이 더 빨리 수행될 수도 있습니다. 일회성 분석 작업은 또한 운영 환경의 코드에서 일반적인 형태로 나타나며, 예를 들어 새로운 데이터가 들어올 때마다 이미 존재하는 모델로 해당 데이터 집합에 대한 스코어링 작업을 수행하는 것과 같은 작업을 볼 수 있습니다. 이러한 경우, 최적의 솔루션을 찾기 위해 어느 정도의 벤치 마크를 실행해야 할 필요가 있습니다.
마지막 섹션에서 rxImport를 사용하여 6개월 분의 CSV 파일을 단일 XDF 파일로 변환합니다. 우리는 이제 이 XDF 데이터 파일을 가리키는 nyc_xdf 라는 R 객체를 만들 수 있습니다. 우리는 RxXdfData 함수에 해당 XDF 파일에 대한 경로를 제공함으로써 해당 작업을 수행합니다. 다음으로 nyc_xdf 객체에 대해 rxSummary 함수를 실행하여, 이 데이터 집합의 요약 정보을 살펴 보겠습니다. rxSummary 함수는 다른 많은 R 함수에서 사용되는 것과 동일한 공식 표기법(formula notation)을 사용합니다. 이 경우 ~ fare_amount 식은 fare_amount 열에 대한 요약 정보 만을 보고 싶다는 의미입니다. Base R의 Summary 함수처럼 rxSummary는 각 열의 유형에 따라 다른 출력을 표시합니다. fare_amount는 숫자 열이므로 숫자에 대한 요약 통계 정보가 표시됩니다.
input_xdf <- 'yellow_tripdata_2016.xdf'
nyc_xdf <- RxXdfData(input_xdf)
system.time(
rxsum_xdf <- rxSummary( ~ fare_amount, nyc_xdf) # fare amount에 대한 통계 요약 제공
)
rxsum_xdf
Rows Processed: 69406520
user system elapsed
0.00 0.00 1.68
Call:
rxSummary(formula = ~fare_amount, data = nyc_xdf)
Summary Statistics Results for: ~fare_amount
Data: nyc_xdf (RxXdfData Data Source)
File name: yellow_tripdata_2016.xdf
Number of valid observations: 69406520
Name Mean StdDev Min Max ValidObs MissingObs
fare_amount 12.91626 128.1172 -957.6 628544.7 69406520 0
XDF 변환을 건너 뛰고, 원본 CSV 파일에 동일한 분석을 수행할 수도 있음을 알아야 합니다. 이 때, CSV 파일은 월단위로 별도 저장되어 있으므로, CSV 파일을 하나로 결합하지 않을 경우, 단일 rxSummary 명령으로는 단지 달 동안의 요약 정보만 얻을 수 있습니다. 그렇지만 이것 만으로도 성능을 검증하려는 우리의 목적 달성에는 충분할 것입니다. CSV 파일에 대하여 rxSummary를 실행하려면, RxTextData (XDF 파일의 경우에서 사용한 RxXdfData 대신)를 사용하여 CSV 파일에 대한 포인터를 만들고, colClasses 인수를 사용하여 열 유형을 직접 전달합니다. 나머지는 동일합니다. 실행 시에 CSV 파일의 요약을 만들어 내는 시간이 상대적으로 꽤 오래 걸리는 점에 유의하십시오(CSV 파일이 한 달의 데이터로만 구성 되었음에도 불구하고).
input_csv <- 'yellow_tripdata_2016-01.csv' # CSV 파일들을 결합하지 않으면 한 달의 데이터만 사용 가능
nyc_csv <- RxTextData(input_csv, colClasses = col_classes) # CSV 파일 참조 및 열 정보 제공
system.time(
rxsum_csv <- rxSummary( ~ fare_amount, nyc_csv) # fare amount에 대한 통계 요약 제공
)
rxsum_csv
Rows Processed: 10906858
user system elapsed
0.00 0.00 42.58
Call:
rxSummary(formula = ~fare_amount, data = nyc_csv)
Summary Statistics Results for: ~fare_amount
Data: nyc_csv (RxTextData Data Source)
File name: yellow_tripdata_2016-01.csv
Number of valid observations: 10906858
Name Mean StdDev Min Max ValidObs MissingObs
fare_amount 12.48693 35.564 -957.6 111270.9 10906858 0
마지막 예제는 RevoScaleR이 플랫 파일(XDF 파일보다 처리 시간이 오래 걸리지만)을 직접 사용할 수 있음을 보여주기 위해 실행되습니다. 그렇지만 이후의 분석에는 매우 많은 데이터 처리가 필요하고 다양한 분석 함수들이 실행되기 때문에, 지금부터는 XDF 파일만을 사용하도록 합니다. 이렇게 함으로써 우리는 더 빠른 런타임을 통한 이익을 얻을 수 있습니다.