지역 순서 재조정
다음 단계의 작업으로, 승차 및 하차 지역과 요금, 여행 거리, 교통량 및 팁과 같은 다른 변수 사이의 패턴을 찾아 보겠습니다. 교통량(traffic)이 운행 시간이 예상보다 오래 걸리게 하는 가장 일반적인 이유라고 가정하에, 주행 기간과 거리의 비율을 보고 교통량(traffic)을 추정합니다.
이 분석을 위해 우리는 rxCube와 rxCrossTabs을 사용합니다. 둘 다 rxSummary와 매우 유사하지만 더 적은 통계 요약을 반환하므로 더 빠르게 실행됩니다. y ~ u:v를 수식으로 사용하면, rxCrossTabs는 총수와 합계를 반환하고, rxCube는 열 u와 v의 조합으로 나누어 진 열 y의 총수와 평균을 반환합니다. 두 함수의 또 다른 중요한 차이점은 rxCrossTabs는 배열을 반환하지만 rxCube data.frame을 반환한다는 점입니다. 문제를 어떻게 해결 하려는지에 따라, 우리는 둘 중 하나를 선택할 수 있습니다(물론 "다시 모양을 바꾸어" 서로 결과 형식을 변환할 수는 있지만, 이는 추가 작업이 필요합니다).
실제로 이것이 무엇을 의미하는지 보겠습니다. rxCrossTabs를 사용하여 trip_distance에 대한 합계와 총수를 얻고, pickup_nb와 dropoff_nb로 나눈다. 평균을 얻기 위해 합계를 총수로 바로 나눌 수 있습니다. 그 결과를 주행 거리 행렬(distance matrix)이라고 부르며, seriation 라이브러리의 seriate 함수에 입력하여, 가까운 지역들이 서로 인접하여 나타나게 할 수 있습니다(현재는 알파벳순으로 정렬되어 있으며, 이는 R에서 별도 지정되지 않은 경우 기본적으로 사용하는 factor의 level 정렬 순서 입니다).
rxct <- rxCrossTabs(trip_distance ~ pickup_nb:dropoff_nb, mht_xdf)
res <- rxct$sums$trip_distance / rxct$counts$trip_distance
library(seriation)
res[which(is.nan(res))] <- mean(res, na.rm = TRUE)
nb_order <- seriate(res)
잠시 후 nb_order를 사용할 것입니다. 그렇지만 먼저 rxCube를 사용하여 trip_distance에 대한 총수와 평균, 운행시 마일당 택시에서 보내는 시간을 나타내는 새로운 데이터 포인트와 tip_percent를 얻도록 하겠습니다. 위의 예제에서, 우리는 반환 객체로 행렬을 원했기 때문에, rxCrossTabs를 사용했기 때문에, 결과를 seriate로 전달할 수 있었습니다. 이번에는 ggplot2를 사용하여 플로팅하는 데 사용할 계획이기 때문에, rxCube를 사용하여 data.frame을 얻도록 합니다. ggplot2에서는 긴 data.frame을 입력으로 사용하는 것이 넓은 matirx를 쓰는 것과 비교했을 때 더 코딩하기가 쉽습니다.
rxc1 <- rxCube(trip_distance ~ pickup_nb:dropoff_nb, mht_xdf)
rxc2 <- rxCube(minutes_per_mile ~ pickup_nb:dropoff_nb, mht_xdf,
transforms = list(minutes_per_mile = (trip_duration/60)/trip_distance))
rxc3 <- rxCube(tip_percent ~ pickup_nb:dropoff_nb, mht_xdf)
res <- bind_cols(list(rxc1, rxc2, rxc3))
res <- res[ , c('pickup_nb', 'dropoff_nb', 'trip_distance', 'minutes_per_mile', 'tip_percent')]
head(res)
# A tibble: 6 × 5
pickup_nb dropoff_nb trip_distance minutes_per_mile tip_percent
<fctr> <fctr> <dbl> <dbl> <dbl>
1 Battery Park Battery Park 1.015857 11.579629 11.394900
2 Carnegie Hill Battery Park 8.570623 3.944350 12.391030
3 Central Park Battery Park 6.277666 5.243241 10.326531
4 Chelsea Battery Park 2.995946 5.169887 11.992151
5 Chinatown Battery Park 1.771597 9.001305 10.292683
6 Clinton Battery Park 3.993806 4.839858 9.794098
위의 결과를 plotting하여 보다 흥미로운 추세를 볼 수 있습니다.
library(ggplot2)
ggplot(res, aes(pickup_nb, dropoff_nb)) +
geom_tile(aes(fill = trip_distance), colour = "white") +
theme(axis.text.x = element_text(angle = 60, hjust = 1)) +
scale_fill_gradient(low = "white", high = "steelblue") +
coord_fixed(ratio = .9)

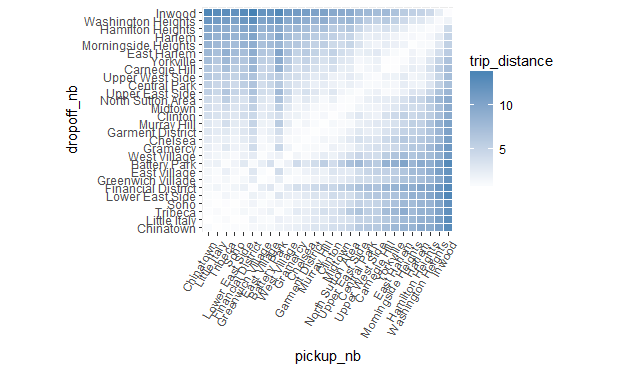
위의 polt 챠트의 문제는, 지역의 순서 (알파벳 순서)로, 챠트의 내용을 다소 임의적이며 쓸모 없도록 만들어 버립니다. 그러나 위에서 언급하였듯이 seriate 함수를 사용하여 지역에 대하여 보다 자연스러운 정렬 순서를 찾았으므로, 이를 사용하여 위의 챠트를 보다 적합한 방식으로 재정렬 할 수 있습니다. plot에서 지역의 순서를 바꾸려면, nb_order에 주어진 순서대로 factor의 level에 대한 정렬을 바꾸면됩니다.
newlevs <- levels(res$pickup_nb)[unlist(nb_order)]
res$pickup_nb <- factor(res$pickup_nb, levels = unique(newlevs))
res$dropoff_nb <- factor(res$dropoff_nb, levels = unique(newlevs))
library(ggplot2)
ggplot(res, aes(pickup_nb, dropoff_nb)) +
geom_tile(aes(fill = trip_distance), colour = "white") +
theme(axis.text.x = element_text(angle = 60, hjust = 1)) +
scale_fill_gradient(low = "white", high = "steelblue") +
coord_fixed(ratio = .9)