운행 거리 조사
데이터는 보통 지저분 하기 때문에 일을 처리 하기에 앞서서 정제를 해야하는 경우가 많습니다. 데이터에 대한 요약 및 스냅 샷에 대한 작업을 살퍼보면서, 데이터를 어떻게 정리해야 하는지 알 수 있습니다. 다음은 몇 가지 제안 사항입니다.
- 누락된 값들이 제대로 반영 되었습니까? 플랫 파일에서 누락값은 종종 NA 와는 다르게 표현됩니다. 예를 들어, 누락된 숫자열이 빈 셀이나 NULL 또는 999를 사용하여 표현되는 것처럼, 문자열의 누락된 값은 빈 항목이나 '기타' 또는 'n/a'와 같은 포괄적인 용어로 표현되어 있는 셀을 가질 수 있습니다. 또는 보다 상세한 누락값에 대한 구분을 표시하기 위해 다른 코드가 사용될 수도 있습니다(정보가 관련이 없기 때문에 누락 또는 데이터 또는 정보가 제공되지 않았기 때문에 누락 등). R에서 누락된 값을 기록하기 위하여 NA를 사요할 때에는 이러한 차이를 고려하는 것이 중요합니다.
- 열 유형이 예상과 일치합니까? 이것은 중요한 고려 사항이며, 데이터를 읽기 전에 명시적으로 열 유형을 제공함으로써 이를 관리하여야 합니다. 이는 불필요한 처리, 특히 R이 필요하지 않을 때 factor로 열에서 읽는 경우 발생하는 처리를 피하기 때문에 선호되는 방법입니다. factor로 지정된 높은 카디널리티가 있는 열은 R 세션에 많은 오버 헤드를 주게 됩니다. 이러한 열은 보통 factor일 필요가 없으며, 정수 또는 문자열로 남아 있어야만 합니다. 어떤 열이 factor가 되어야 하는지 어떤 열이 아닌지를 미리 알지 못하거나, 열을 factor로 변환하기 전에 정제를 할 필요가 있는 경우, rxImport를 실행 시에 stringsAsFactors = FALSE로 설정하거나 숫자가 아닌 모든 열을 문자 열로 지정하여 문자열을 factor로 자동 변환되는 것을 억제 할 수 있습니다.
- 데이터에 이상값이 존재하고 있고 이 값이 타당하게 보입니까? 흔히 이상값인지 아닌지에 대한 문제는 우리가 데이터에 대하여 얼마나 이해하고 있는지, 데이터의 평균 패턴과의 편차에 대하여 얼마나 허용할 것인지에 달려 있습니다. 뉴욕 택시 데이터 세트에서는 다음과 같은 경우들이 고려되어야 합니다. (1) 승객이 택시를 타고 하루 종일 타고 다니면서 운전 기사에게 기다리라고 요청하면서 여러 용무를 보는 경우가 있을 수 있습니다. (2) 승객이 40 달러의 운행 요금에 대하여 5 달러를 팁으로 주려다가 실수로 5 번을 두 번 누르고 55 달러를 지불할 수 있습니다. (3) 승객은 운전자와 다투고는 요금을 지불하지 않고 떠날 수 있습니다. (4) 여러 건의 운행에 대하여 특정한 한 사람이 비용을 지불하거나, 한 건의 운행에 대하여 여러 명이 각자 자기 요금많을 지불할 수 있습니다. 이 때, 어떤 사람은 카드로 또 어떤 사람은 현금으로 지불합니다. (5) 운전자는 승객이 하차한 이후에도 우발적으로 거리계를 계속 작동시키고 있을 수 있습니다. (6) 기계의 오류로 인해 기록된 데이터가 없거나 잘못된 데이터가 발생할 수 있습니다. 이 모든 경우에 있어서, 우리가 쉽게 이러한 활동들을 포착할 수 있다고 가정하더라도(데이터 포인트들의 조합 일부가 비정상적인 범위 내에 있기 때문에), 이러한 값이 타당한지에 대한 부분은 우리가 분석하고자 하는 목적이 무엇인지에 달려 있습니다. 이상값 하나는 어떤 분석에서는 잡음이 되지만 다른 분석에는서 관심을 가져야 하는 흥미로운 지점일 수 있는 것입니다.
이제 특이값 후보치를 가진 데이터를 얻었으므로 특정 패턴을 조사해 볼 수 있습니다. 예를 들어, trip_distance의 히스토그램을 그릴 수 있고 대다수는 5 마일 미만으로 거의 모든 여행이 20 마일 미만의 거리를 여행했다는 것을 알 수 있습니다. .
rxHistogram( ~ trip_distance, nyc_xdf, startVal = 0, endVal = 25, histType = "Percent", numBreaks = 20)
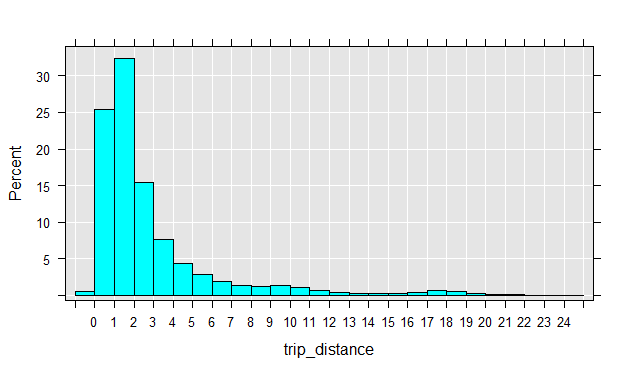
16과 20마일 사이의 주행 거리에서 두 번째 피크가 있으며, 이는 좀 더 살펴볼 필요가 있습니다. 우리는 승객이 어느 지역에서 어느 지역으로 이동하는 지를 조사함으로써 이것을 확인할 수 있습니다.
rxs <- rxSummary( ~ pickup_nhood:dropoff_nhood, nyc_xdf, rowSelection = (trip_distance > 15 & trip_distance < 22))
head(arrange(rxs$categorical[[1]], desc(Counts)), 10)
pickup_nhood dropoff_nhood Counts
1 Midtown Gravesend-Sheepshead Bay 2517
2 Upper East Side Gravesend-Sheepshead Bay 1090
3 Midtown Douglastown-Little Neck 1013
4 Midtown Midtown 978
5 Garment District Gravesend-Sheepshead Bay 911
6 Midtown Bensonhurst 878
7 Gramercy Gravesend-Sheepshead Bay 784
8 Jamaica Upper West Side 775
9 Chelsea Gravesend-Sheepshead Bay 729
10 Midtown Bay Ridge 687
보이는 것처럼, Gravesend-Sheepshead Bay는 목적지로 자주 보이며, 놀랍게도, 탑승 포인트로는 아닌 것으로 나타납니다. 또한 JFK 공항과 가장 가까운 지역인 Jamaica에서 출발하거나, 도착하는 주행 기록들을 볼 수 있습니다.