이상값 조사
RevoScaleR을 사용하여 이상치에 대한 데이터를 검사하는 방법을 살펴 보겠습니다. 여기서의 우리 접근 방식은 다소 원시적인 것이지만, 이는 도구를 사용하는 방법을 보여주기 위한 것입니다. rxDataStep 및 rowSelection 인수를 사용하여 이상값 후보가 될 모든 데이터 요소를 추출합니다. outFile 인수를 빈 값으로 설정하여, 결과 데이터 집합을 odd_trips라는 이름의 data.frame으로 출력합니다. 마지막으로, 우리가 아웃 라이어 선택 기준을 너무 넓게 잡았을 경우에는 결과인 data.frame에 지나치게 많은 행이 존재할 수 있습니다(이는 메모리상에 문제를 발생키시고 플롯 작성 및 기타 요약을 생성하는 속도를 느리게 함). 따라서 새로운 열 u를 만들고 0에서 1 사이의 임의의 균일하게 분포된 숫자를 채우도록 한 다음, rowSelection 조건에 u <.05를 추가합니다. 이 숫자를 조정하여 더 작은 data.frame(0에 가까운 기준값) 또는 더 큰 data.frame (1에 가까운 기준값)으로 데이터 사이즈를 조정할 수 있습니다.
# outFile argument missing means we output to data.frame
odd_trips <- rxDataStep(nyc_xdf, rowSelection = (
u < .05 & ( # we can adjust this if the data gets too big
(trip_distance > 50 | trip_distance <= 0) |
(passenger_count > 5 | passenger_count == 0) |
(fare_amount > 5000 | fare_amount <= 0)
)), transforms = list(u = runif(.rxNumRows)))
print(dim(odd_trips))
[1] 93750 32
이상값 후보들을 가진 데이터 집합은 data.frame이기 때문에, Base R의 어떤 함수로도 이를 검사 할 수 있습니다. 예를 들어, odd_trips를 50 마일을 초과하는 거리로만 제한하고, 승객이 지불한 운임의 히스토그램을 그리고, 여행에 10 분 이상 걸렸는지 아닌지에 따라 색상을 지정합니다.
odd_trips %>%
filter(trip_distance > 50) %>%
ggplot() -> p
p + geom_histogram(aes(x = fare_amount, fill = trip_duration <= 10*60), binwidth = 10) +
xlim(0, 500) + coord_fixed(ratio = 25)
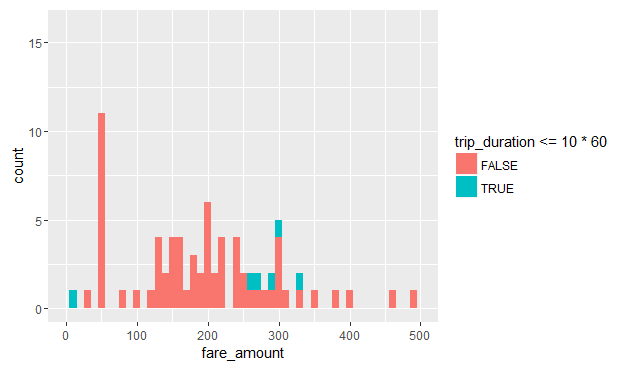
보시는 것처럼, 대다수의 50 마일 이상의 주행거리 건들이, 대부분 10분 이상 운행되었음에도, 비용이 없거나 거의 들지 않았습니다. 이러한 운행 데이터가 기계의 오류인지 또는 사람의 실수로 인한 것인지 여부는 확실하지 않지만, 예를 들어 이 분석이 택시를 소유한 특정 회사를 대상으로 할 경우라면, 이를 확인하기 위하여 더 많은 조사가 아마도 이어서 진행될 것입니다.